Segurança e Cibersegurança
A segurança em geral envolve a proteção de ativos contra diversas ameaças representadas por vulnerabilidades inerentes. Os processos de segurança geralmente tratam da implementação de mecanismos de segurança (também chamados de contramedidas) que ajudam a reduzir o risco representado por essas vulnerabilidades.
Cibersegurança é a proteção de todos os ativos que podem ser alcançados pelo ciberespaço. O que engloba sistemas de computadores, informações armazenadas ou em trânsito, dispositivos e os usuários destas tecnologias.
Para um ativo ser definido como protegido alguns atributos devem ser mantidos, são estes:
- Confidencialidade
- Um ativo não pode ser acessado por uma entidade não autorizada.
- Integridade
- Um ativo não pode ser alterado por uma entidade não autorizada.
- Disponibilidade
- O acesso a um ativo não pode ser impossibilitado por terceiros.
Estes atributos são conhecidos como a tríade CIA (Confidentiality, Integrality, Availability) sendo um modelo designado a guiar as politicas de cibersegurança de uma organização.

Definições mais recentes argumentam que a tríade precisa de novos atributos, dessa forma, adicionam outras características como:
- Autenticidade
- Um ativo deve conseguir comprovar sua legitimidade e origem.
- Não repúdio
- Uma entidade não pode negar a autoria de uma ação ou posse de um ativo.
Padrões de Cibersegurança
Organizações internacionais, como a International Organization for Standardization (ISO) e o National Institute of Standards and Technology (NIST), desempenham um papel fundamental no desenvolvimento de padrões e diretrizes amplamente reconhecidos na comunidade de cibersegurança. Esses padrões frequentemente convergem em princípios fundamentais, processos e boas práticas, fornecendo um alicerce robusto para a segurança cibernética.
O NIST, uma agência federal dos Estados Unidos, é uma referência na produção de padrões e diretrizes para diversas áreas, com destaque para a cibersegurança. Seus documentos orientativos são vitais para organizações que buscam fortalecer sua postura de segurança.
Um exemplo notável é o NIST Cybersecurity Framework (CSF), uma estrutura aberta e baseada em princípios, desenvolvida em resposta à crescente necessidade de orientações comuns entre organizações para o gerenciamento de riscos cibernéticos. O CSF proporciona uma linguagem compartilhada para compreender e comunicar práticas de gestão de riscos cibernéticos.
O CSF é estruturado em cinco funções principais, cada uma centrada em uma área crítica de foco:
- Identify (Identificar): Desenvolver uma compreensão das atividades, ativos e recursos críticos para a organização.
- Protect (Proteger): Implementar salvaguardas para assegurar a entrega segura dos serviços essenciais.
- Detect (Detectar): Desenvolver e implementar atividades de monitoramento e detecção para identificar incidentes de segurança.
- Respond (Responder): Desenvolver e implementar planos de resposta a incidentes para lidar eficazmente com eventos de segurança.
- Recover (Recuperar): Desenvolver e implementar planos de recuperação para restaurar as operações normais após um incidente.
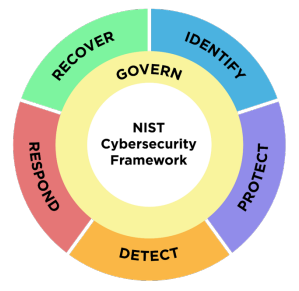
A versão 2.0 do framework, lançada em agosto de 2023, introduziu a governança como uma nova função crítica que abrange todo o processo. O documento completo pode ser acessado em: https://doi.org/10.6028/NIST.CSWP.29.ipd
Áreas da Cibersegurança
A cibersegurança, sem dúvida, engloba uma ampla gama de campos de estudo e áreas de atuação, muitas das quais apresentam enfoques distintos, embora frequentemente interdependentes. Abaixo, destacamos algumas dessas áreas fundamentais:
Segurança da Informação
A Segurança da Informação abrange a proteção de dados sensíveis da organização, incluindo informações confidenciais, registros de clientes e propriedade intelectual. Essa área envolve a implementação de políticas, procedimentos, tecnologias avançadas e treinamento contínuo para assegurar a confidencialidade, integridade e disponibilidade dos dados.
Segurança Ofensiva (Ethical Hacking / Penetration Testing)
A Segurança Ofensiva consiste na avaliação proativa da segurança de sistemas, redes e aplicativos, simulando potenciais ataques. Profissionais nessa área atuam como "hackers éticos" (odeio esse nome), identificando vulnerabilidades para corrigi-las antes que criminosos possam explorá-las.
Segurança de Redes
A Segurança de Redes concentra-se na proteção da infraestrutura de rede, abrangendo dispositivos, protocolos e tráfego de dados. Profissionais dessa área implementam medidas como firewalls, VPNs e sistemas de detecção de intrusões (IDS) para garantir uma comunicação segura.
Segurança de Sistemas:
A Segurança de Sistemas visa proteger servidores, sistemas operacionais e aplicativos contra ameaças cibernéticas. Isso inclui configuração segura, monitoramento de logs, aplicação de patches e gestão de contas de usuário.
Segurança em Nuvem:
A Segurança em Nuvem é especializada na proteção de ambientes e dados armazenados em serviços de nuvem. Profissionais dessa área implementam controles específicos para garantir a segurança dos recursos hospedados na nuvem.
Segurança de Aplicações (Application Security):
Essa área foca na proteção de software contra ameaças, utilizando testes de segurança de aplicativos, revisões de código e a implementação de práticas seguras de desenvolvimento.
Forense Digital:
A Forense Digital é um campo especializado que aplica técnicas investigativas e analíticas para coletar, preservar, analisar e apresentar evidências digitais relacionadas a incidentes cibernéticos, crimes digitais ou disputas legais.
Gestão de Identidade e Acesso (Identity and Access Management - IAM):
Concentrando-se na administração de identidades digitais e no controle de acesso a sistemas e dados, essa área inclui autenticação, autorização e gerenciamento de privilégios.
Criptografia:
A Criptografia é uma disciplina especializada na prática de converter dados ou informações legíveis em um formato ilegível por meio de algoritmos e chaves. Seu principal objetivo é garantir que apenas partes autorizadas possam acessar e compreender a informação original. A criptografia é essencial para proteger dados confidenciais em transações financeiras, comunicações sensíveis e informações pessoais, evitando o acesso de terceiros não autorizados. Suas aplicações são vastas e estão integradas em muitos aspectos da cibersegurança e da privacidade digital.
Gestão de Riscos e Conformidade:
A Gestão de Riscos e Conformidade preocupa-se em avaliar e mitigar os riscos de segurança cibernética, garantindo que as práticas da organização estejam em conformidade com regulamentações, como a GDPR e LGPD, bem como padrões de segurança reconhecidos. Essa área desempenha um papel crucial na construção de uma postura de segurança robusta e na adaptação contínua às exigências legais e normativas.
Hacker:
Leia o artigo Tipos de Hacker para entender melhor sobre o termo e os diferentes tipos de hackers existentes.
Essencial de Linux
Autor: Lucas Albano
Neste artigo vamos explorar conceitos básicos de sistemas Linux. Além disso, vamos apresentar a distribuição Kali Linux, uma distribuição focada em segurança da informação e testes de penetração.
Linux
No contexto da cibersegurança, o conhecimento e a compreensão de sistemas operacionais desempenha um papel crucial. Entre as várias opções disponíveis, o Linux se destaca como uma escolha popular entre profissionais de segurança da informação e entusiastas de tecnologia. Esta seção oferece uma visão geral do Linux, desde sua definição até sua relevância no campo da cibersegurança.
O que é Linux
GNU/Linux é um sistema operacional de código aberto distribuído gratuitamente e pode ser modificado e redistribuído por qualquer pessoa de acordo com os termos da licença GNU General Public License (GPL). Ele oferece uma alternativa viável e poderosa aos sistemas operacionais comerciais, como Windows e macOS. O principal destaque do GNU/Linux é sua flexibilidade e capacidade de personalização, o que o torna uma escolha popular entre desenvolvedores, administradores de sistemas e entusiastas de tecnologia em geral.
Linux foi o nome dado ao núcleo de sistema operacional criado por Linus Torvalds. Por extensão, sistemas operacionais que usam o núcleo Linux são chamados genericamente de Linux. Entretanto, a Free Software Foundation afirma que tais sistemas operacionais são, na verdade, sistemas GNU, e o nome mais adequado para tais sistemas é GNU/Linux, uma vez que grande parte do código-fonte dos sistemas operacionais baseados em Linux são ferramentas do projeto GNU.
O Linux oferece uma ampla variedade de distribuições, conhecidas como "distros", que atendem a diferentes necessidades e preferências dos usuários. Algumas das distros mais populares incluem Ubuntu, Fedora, Debian e CentOS, cada uma com suas próprias características e conjuntos de software.
Uma Breve História do Linux
O Linux foi criado por Linus Torvalds no início dos anos 90, enquanto ele era um estudante de informática na Universidade de Helsinki, na Finlândia. Torvalds havia se matriculado em um curso de UNIX, e um dos textos obrigatórios era Operating Systems: Design and Implementation escrito por Andrew S. Tanenbaum. O livro incluía uma cópia do sistema operacional MINIX de Tanenbaum, no entanto, o licenciamento do MINIX o restringia ao uso educacional. Assim, Torvalds decidiu iniciar um projeto pessoal para desenvolver um kernel similar ao UNIX, mas livre e de código aberto.
Em 1991, Linus Torvalds lançou a primeira versão oficial do kernel do Linux, a versão 0.02. No ano de 1992, ele mudou a licença do núcleo Linux, de uma licença própria para uma licença livre compatível com a GPL do projeto GNU. Isso atraiu uma comunidade de desenvolvedores entusiastas, que contribuíram para o desenvolvimento do sistema operacional, adicionando novos recursos, corrigindo bugs e adaptando-o para diferentes necessidades e dispositivos.
O Linux rapidamente ganhou popularidade entre os entusiastas de computadores e desenvolvedores de software. Empresas também começaram a adotá-lo, principalmente devido à sua estabilidade, segurança e custo zero de licenciamento. Organizações como a Red Hat, a SUSE e a Canonical desenvolveram distribuições Linux voltadas para o mercado empresarial, oferecendo suporte comercial e serviços adicionais.
Nos anos seguintes, o Linux expandiu-se para uma variedade de dispositivos, desde servidores e supercomputadores até smartphones, eletrodomésticos e dispositivos de Internet das Coisas (IoT). Uma das distribuições mais populares, o Ubuntu, tornou-se especialmente conhecida por sua facilidade de uso e suporte à comunidade.
O sucesso do Linux não se limita apenas ao software. Ele também inspirou uma filosofia de colaboração aberta e compartilhamento de conhecimento, que se tornou fundamental para muitos projetos de código aberto e para a própria cultura da Internet. Hoje, o Linux é uma parte fundamental do panorama da tecnologia, alimentando uma ampla variedade de dispositivos e sistemas em todo o mundo.
Por que usar Linux?
O uso do Linux no contexto da cibersegurança vai além de uma mera escolha de sistema operacional; é uma decisão estratégica fundamentada em uma série de vantagens e características que o tornam uma plataforma ideal para profissionais e estudantes de cibersegurança.
Primeiramente, o Linux é conhecido pela sua segurança robusta. Sua estrutura de permissões granulares e seu modelo de segurança baseado em princípios de acesso mínimo são essenciais para mitigar ameaças potenciais. Além disso, a comunidade de código aberto que sustenta o Linux está constantemente monitorando e corrigindo vulnerabilidades, garantindo atualizações regulares que fornecem uma maior confiança na integridade do sistema. Isso contrasta com sistemas operacionais proprietários, nos quais os detalhes do código são mantidos em segredo, dificultando a identificação e correção de possíveis brechas de segurança.
Além disso, a vasta gama de ferramentas de segurança disponíveis para o Linux é incomparável. Desde firewalls e sistemas de detecção de intrusões até criptografia e ferramentas de análise forense, o ecossistema do Linux oferece uma variedade de soluções para proteger sistemas e redes contra ameaças cibernéticas. Essas ferramentas são frequentemente desenvolvidas e mantidas pela comunidade de código aberto, garantindo atualizações regulares e suporte contínuo.
Outro aspecto crucial é a flexibilidade e personalização oferecidas pelo Linux. Estudantes de cibersegurança podem criar ambientes de laboratório personalizados, replicando cenários de ataque e defesa para fins de aprendizado e treinamento. A capacidade de personalizar e ajustar o sistema operacional de acordo com as necessidades específicas de segurança de cada projeto ou organização é uma vantagem significativa em um campo onde a adaptabilidade e a agilidade são essenciais.
O Linux também é altamente compatível com uma ampla variedade de hardware, o que é fundamental em ambientes de cibersegurança que frequentemente envolvem o uso de dispositivos e sistemas diversos. Essa interoperabilidade facilita a integração do Linux em infraestruturas existentes e simplifica a implementação de soluções de segurança em uma variedade de contextos.
Em resumo, o Linux oferece uma combinação única de segurança, transparência, flexibilidade e compatibilidade que o torna uma escolha ideal para estudantes e profissionais de cibersegurança. Ao dominar as nuances desse sistema operacional, profissionais e estudantes podem desenvolver habilidades essenciais e contribuir para a construção de um ambiente digital mais seguro e resiliente.
Kali Linux
O Kali Linux é uma distribuição Linux especializada projetada especificamente para testes de penetração e auditoria de segurança. Ele é desenvolvido e mantido pela Offensive Security, uma empresa de segurança cibernética reconhecida por suas certificações e treinamentos em segurança.
O que distingue o Kali Linux de outras distribuições é sua ampla gama de ferramentas de segurança pré-instaladas e otimizadas para fins de testes de penetração. Essas ferramentas abrangem uma variedade de áreas, incluindo análise de vulnerabilidades, exploração de sistemas, análise forense digital, engenharia reversa e muito mais.
Profissionais de segurança optam por utilizar o Kali Linux por várias razões. Primeiramente, a conveniência de ter um conjunto abrangente de ferramentas de segurança disponíveis em uma única distribuição simplifica significativamente o processo de realização de testes de penetração e auditoria de segurança. Em vez de instalar e configurar cada ferramenta individualmente, o Kali Linux fornece um ambiente pronto para uso, permitindo que os profissionais se concentrem diretamente em suas tarefas de segurança.
Outro aspecto importante é o suporte da comunidade e os recursos educacionais disponíveis para os usuários do Kali Linux. A Offensive Security oferece uma variedade de recursos, incluindo documentação abrangente, fóruns de discussão, blogs e cursos de treinamento, que ajudam os profissionais de segurança a aproveitar ao máximo as capacidades do Kali Linux e a aprimorar suas habilidades em testes de penetração e auditoria de segurança.
Além disso, o Kali Linux é altamente personalizável e pode ser adaptado às necessidades específicas de cada usuário. Os profissionais de segurança podem adicionar ou remover ferramentas conforme necessário, configurar o sistema de acordo com as políticas de segurança da organização e personalizar a interface de usuário para atender às suas preferências individuais.
Tutorial de Instalação do Kali Linux:
Tutorial oficial para instalação do Kali no VirtualBox: https://www.kali.org/docs/virtualization/install-virtualbox-guest-vm/
Passo 1: Baixar o Kali Linux
- Acesse o site oficial do Kali Linux em https://www.kali.org/get-kali/#kali-platforms e baixe a imagem ISO mais recente do Kali Linux para a plataforma desejada. O Kali possui versões pré-montadas para Máquinas Virtuais e também possui uma distribuição para Windows Subsystem Linux.
Instalação em Máquina Virtual
Passo 2: Criar uma nova máquina com o arquivo pré-montado
- Extraia o arquivo baixado e crie uma nova máquina virtual em seu software de virtualização a partir deste. O processo exato para criar uma nova máquina virtual pode mudar dependendo da plataforma e software de virtualização utilizado, contudo, não é um processo muito complexo e pode ser facilmente descoberto nos tutoriais oficiais. Tutorial oficial do Virtual Box: (https://www.virtualbox.org/manual/ch01.html#create-vm-wizard). Você também pode desejar alterar as configurações padrões, como memória e CPUs alocadas para a VM.
Passo 3: Iniciar o Kali Linux
- Após isto, basta iniciar a máquina e tudo já estará pronto. O usuário padrão é
kalie a senha padrão ékali. Para mais detalhes leia a documentação oficial.
Dica: Pode ser necessário configurar o teclado para o padrão brasileiro. Para isto utilize o comando
setxkbmap br abnt2.
Instalação em Hardware
Passo 2: Criar um dispositivo de inicialização
- Grave a imagem ISO em um dispositivo de inicialização, como um DVD ou unidade flash USB. Você pode usar ferramentas como Rufus (para Windows) ou Etcher (para Linux e macOS) para criar um dispositivo de inicialização bootável.
Passo 3: Iniciar o computador a partir do dispositivo de inicialização
- Reinicie o computador e inicie a partir do dispositivo de inicialização que você criou.
Passo 4: Iniciar o processo de instalação
- Uma vez iniciado a partir do dispositivo de inicialização, você será apresentado ao menu de inicialização do Kali Linux. Selecione a opção "Graphical Install" (Instalação Gráfica) e siga as instruções na tela.
Passo 5: Configurar o sistema
- Durante o processo de instalação, você será solicitado a selecionar o idioma, localização, layout do teclado e configurar o nome do host e a senha de root.
Passo 6: Particionamento do disco
- Selecione o método de particionamento de disco que melhor atenda às suas necessidades. Você pode optar por particionamento automático ou manual, dependendo de sua preferência e conhecimento.
Passo 7: Concluir a instalação
- Após configurar todas as opções, o instalador irá copiar os arquivos necessários e configurar o sistema. Uma vez concluído, reinicie o computador e remova o dispositivo de inicialização.
Passo 8: Iniciar o Kali Linux
- Após reiniciar, o Kali Linux estará instalado em seu sistema. Faça login com o nome de usuário e senha que você configurou durante a instalação.
Interface de Linha de Comando (CLI)
Em sistemas operacionais Linux, a interface de linha de comando (CLI) desempenha um papel crucial na interação com o sistema. Dois componentes principais dessa interação são os terminais e os shells.
Terminais
Um terminal é uma interface de usuário que permite interagir com um sistema operacional por meio de comandos de texto. Historicamente, os terminais eram dispositivos físicos conectados a mainframes ou minicomputadores por meio de cabos, que exibiam texto e permitiam ao usuário inserir comandos usando um teclado. Eles eram comuns antes do surgimento das interfaces gráficas de usuário (GUIs).
Com o avanço da tecnologia e o surgimento de interfaces gráficas de usuário, os terminais físicos tornaram-se menos comuns. Em vez disso, os sistemas operacionais modernos, como o Linux, macOS e Windows, fornecem emuladores de terminal, que são aplicativos de software que simulam a funcionalidade de um terminal físico em um ambiente gráfico.
Os terminais podem variar em termos de funcionalidades e recursos. Alguns terminais oferecem recursos avançados, como divisão de tela, personalização da aparência e suporte a abas, enquanto outros são mais simples e focados apenas na funcionalidade básica de entrada e saída de texto.
Shells
O shell é um interpretador de comandos que aceita entrada do usuário em forma de texto e os executa como comandos no sistema operacional. Ele age como uma interface entre o usuário e o núcleo do sistema operacional, interpretando os comandos inseridos pelo usuário e realizando as ações correspondentes.
Existem vários shells disponíveis no Linux, cada um com suas próprias características e funcionalidades. Alguns dos shells mais comuns incluem:
- Bash (Bourne Again SHell): O Bash é o shell padrão na maioria das distribuições Linux e é amplamente utilizado devido à sua poderosa capacidade de scripting e suporte a recursos avançados, como expansão de variáveis e histórico de comandos.
- Zsh (Z shell): O Zsh é um shell alternativo que oferece recursos adicionais em comparação com o Bash, como conclusão de comandos mais inteligente, temas personalizáveis e suporte a plugins.
- Fish (Friendly Interactive SHell): O Fish é conhecido por sua interface amigável e intuitiva, com recursos como conclusão automática de comandos, sugestões interativas e coloração de sintaxe.
Cada shell tem sua própria linguagem de script e conjunto de recursos exclusivos, permitindo que os usuários escolham o que melhor se adapta às suas necessidades e preferências.
Em resumo, o terminal é a interface de usuário que fornece acesso ao shell, enquanto o shell é o interpretador de comandos responsável por processar os comandos inseridos pelo usuário e executar as ações correspondentes no sistema operacional. Eles trabalham juntos para fornecer uma maneira eficaz de interagir com o sistema operacional por meio de comandos de texto.
Gerenciador de Pacotes
Os gerenciadores de pacotes são ferramentas essenciais em sistemas operacionais Linux que simplificam o processo de instalação, remoção e atualização de software. Eles automatizam o gerenciamento de dependências e garantem que as versões corretas dos pacotes sejam instaladas para manter o sistema funcionando de forma eficiente e segura.
Existem vários gerenciadores de pacotes disponíveis para diferentes distribuições Linux. Alguns dos mais populares incluem:
- APT (Advanced Package Tool): O APT é comumente usado em distribuições baseadas no Debian, como o Ubuntu. Ele fornece comandos como
apt-geteapt, que podem ser usados para instalar, remover e atualizar pacotes, além de resolver automaticamente dependências. - YUM (Yellowdog Updater, Modified): O YUM é usado principalmente em distribuições baseadas no Red Hat, como Fedora e CentOS. Ele oferece comandos como
yumednf(sucessor do YUM), que simplificam a instalação e atualização de software, gerenciamento de repositórios e resolução de dependências. - Pacman: O Pacman é o gerenciador de pacotes usado no Arch Linux e em suas variantes. Ele permite instalar, remover e atualizar pacotes, além de fornecer um sistema de construção de pacotes para criar e compartilhar software personalizado.
Para instalar um novo aplicativo usando um gerenciador de pacotes, basta executar o comando apropriado seguido pelo nome do pacote. Por exemplo, para instalar o editor de texto "Vim" usando o APT, você pode usar o comando:
sudo apt install vim
Atualização do Sistema:
Para manter o sistema atualizado, é importante atualizar regularmente os pacotes instalados. Isso pode ser feito usando o comando de atualização apropriado para o gerenciador de pacotes em uso. Por exemplo, para atualizar todos os pacotes no sistema usando o APT, você pode usar o comando:
sudo apt update && sudo apt upgrade
O primeiro comando (apt update) atualiza a lista de pacotes disponíveis nos repositórios, enquanto o segundo comando (apt upgrade) instala as atualizações disponíveis.
Sistema de Arquivos
Uma das principais propriedades dos sistemas UNIX nos quais o Linux é baseado é que quase tudo que você precisa identificar em seu sistema (dados, comandos, links simbólicos, dispositivos e diretórios) é representado por itens nos sistemas de arquivos. Dominar a localização e a navegação por esses elementos através do shell é fundamental para quem utiliza o Linux.
A organização dos arquivos no Linux segue uma hierarquia de diretórios, na qual cada diretório pode conter tanto arquivos quanto outros diretórios. Para referenciar qualquer arquivo ou diretório, pode-se utilizar um caminho completo (por exemplo, /home/fireuai/meuarquivo.txt) ou um caminho relativo (por exemplo, se /home/fireuai for o diretório atual, meuarquivo.txt seria suficiente).
A estrutura de diretórios no Linux assemelha-se a uma árvore, tendo o diretório raiz representado por uma única barra (/). Logo abaixo encontram-se diretórios comuns, como bin, dev, home, lib e tmp. Cada um desses diretórios principais, assim como aqueles adicionados ao diretório raiz, podem conter uma infinidade de subdiretórios.
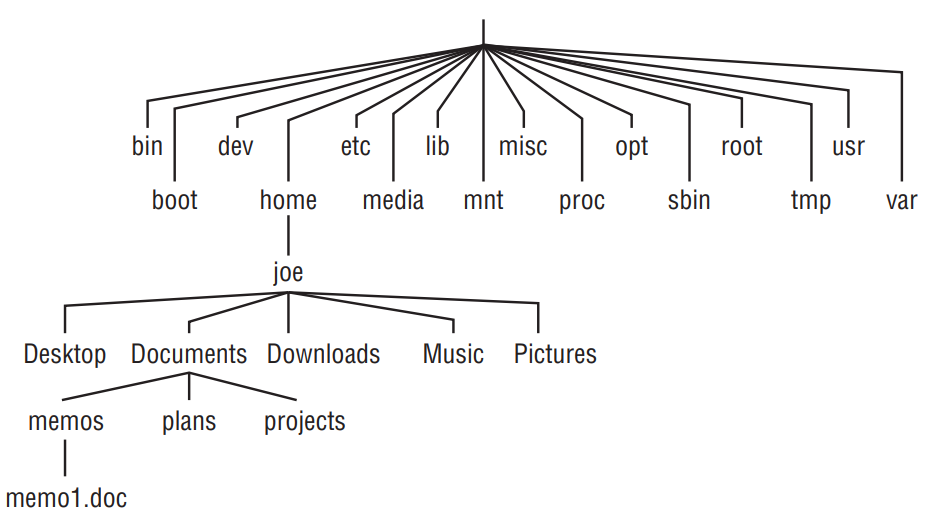
Segue uma breve explicação dos diretórios fundamentais:
-
/ (Raiz): Este é o diretório raiz do sistema de arquivos. Todos os outros diretórios estão contidos dentro dele. É representado por uma barra (
/) e é o ponto de partida para a hierarquia do sistema de arquivos. -
/bin (Binários): Este diretório contém os binários essenciais do sistema, como ls, sort, date e chmod. São os comandos fundamentais necessários para a inicialização e operação do sistema, disponíveis para todos os usuários.
-
/boot (Inicialização): Contém arquivos necessários para a inicialização do sistema, como o kernel do Linux, arquivos de configuração do bootloader (como o GRUB), entre outros.
-
/dev (Dispositivos): Contém arquivos de dispositivo que representam interfaces para dispositivos de hardware conectados ao sistema, como discos rígidos, unidades USB, impressoras, etc. Os usuários podem acessar esses dispositivos diretamente por meio desses arquivos de dispositivos; no entanto, os aplicativos geralmente ocultam os nomes reais dos dispositivos dos usuários finais.
-
/etc (Configurações): Armazena arquivos de configuração do sistema e dos aplicativos. Configurações do sistema, como arquivos de rede, configurações do servidor, entre outros, são encontradas aqui. A maioria desses arquivos são arquivos de texto simples que podem ser editados com qualquer editor de texto se o usuário tiver permissão adequada.
-
/home : Este diretório contém os diretórios pessoais dos usuários. Cada usuário registrado no sistema terá um diretório correspondente aqui para armazenar seus arquivos pessoais. (O usuário root é uma exceção, usando
/rootcomo seu diretório inicial.) -
/media : O diretório
/mediaé usado como ponto de montagem temporário para dispositivos de mídia removíveis, como unidades USB, CDs, DVDs e cartões de memória. Quando um dispositivo removível é conectado ao sistema, ele é automaticamente montado em um subdiretório dentro de/media. Por exemplo, se você conectar um pendrive, ele poderá ser montado em/media/usbou um nome similar. Esse diretório fornece um local conveniente para acessar temporariamente o conteúdo desses dispositivos de mídia. -
/lib (Bibliotecas): Contém bibliotecas compartilhadas necessárias para os programas do sistema e para a inicialização do sistema.
-
/mnt (Montagem): Ponto de montagem para dispositivos de armazenamento temporários ou removíveis, como discos rígidos externos, pendrives, CDs, etc. Alguns sistemas Linux inicializáveis ainda usam esse diretório para montar partições de disco rígido e sistemas de arquivos remotos. Muitas pessoas ainda usam este diretório para montar temporariamente sistemas de arquivos locais ou remotos que não são montados permanentemente.
-
/misc (Miscelânea): O diretório
/miscnão é um diretório padrão no Filesystem Hierarchy Standard (FHS) do Linux. Normalmente, ele é utilizado para armazenar arquivos ou diretórios que não se encaixam em outras categorias específicas. É comum encontrar sistemas onde os administradores usam/misccomo um local genérico para armazenar arquivos que não possuem uma localização mais apropriada. -
/opt (Opcional): Este diretório é usado para instalar pacotes de software adicionais não fornecidos pelos repositórios oficiais da distribuição. É comumente usado por aplicativos comerciais ou de terceiros.
-
/proc (Processos): Contém informações sobre processos em execução no sistema. Os arquivos neste diretório são usados principalmente para interagir com o kernel e obter informações sobre o sistema e os processos em execução.
-
/root (Superusuário): Este diretório é o diretório pessoal do superusuário (root) no sistema Linux. Enquanto o diretório
/homecontém os diretórios pessoais dos usuários normais, o diretório/rooté reservado exclusivamente para o superusuário. O diretório inicial do root não reside abaixo de/homepor motivos de segurança. -
/sbin (Binários do Sistema): Semelhante ao diretório
/bin, mas contém binários essenciais do sistema destinados apenas para uso pelo superusuário (root). -
/tmp (Temporário): Diretório para arquivos temporários. Os arquivos armazenados aqui são geralmente excluídos automaticamente durante a inicialização ou em intervalos regulares.
-
/usr (Recursos do Usuário): Contém recursos compartilhados, como binários, bibliotecas, arquivos de cabeçalho e documentação para aplicativos do usuário. Este diretório é subdividido em
/usr/bin,/usr/lib,/usr/include, entre outros. -
/var (Variável): Armazena dados variáveis do sistema, como logs de sistema (
/var/log), spools de email (/var/mail), arquivos de banco de dados temporários (/var/tmp), entre outros. Em particular, é aqui que você colocaria os arquivos que você compartilha como um servidor FTP(/var/ftp) ou um servidor web (/var/www)``.
Permissões de Arquivos
As permissões de arquivos no sistema operacional Linux são um aspecto crucial da segurança e da gestão de acesso aos arquivos. Elas determinam quem pode ler, escrever ou executar um arquivo ou diretório. As permissões de um arquivo são exibidas ao listar os arquivos em um diretório e geralmente aparecem como uma série de caracteres, como por exemplo: drwxr-xr-x.
Existem três tipos de permissões para arquivos e diretórios:
- Leitura (r): Permite visualizar o conteúdo de um arquivo ou listar o conteúdo de um diretório. Para diretórios, a permissão de leitura também permite listar o conteúdo do diretório.
- Escrita (w): Permite modificar ou excluir um arquivo. Para diretórios, a permissão de escrita permite adicionar, modificar ou excluir arquivos no diretório.
- Execução (x): Permite executar um arquivo como um programa ou acessar um diretório. Para arquivos, a permissão de execução é necessária apenas se o arquivo for um script ou um programa executável. Para diretórios, a permissão de execução permite acessar o conteúdo do diretório.
Além disso, as permissões são definidas para três grupos de usuários:
- Proprietário (owner): O usuário que criou o arquivo ou diretório. O proprietário tem controle total sobre o arquivo, incluindo a capacidade de alterar suas permissões.
- Grupo (group): Um grupo de usuários definido pelo sistema. Todos os usuários pertencentes a esse grupo têm as permissões de grupo no arquivo.
- Outros (others): Todos os outros usuários que não são o proprietário do arquivo e não pertencem ao grupo. Essas são as permissões aplicadas a usuários que não são o proprietário nem fazem parte do grupo.
As permissões são exibidas em um formato composto por 10 caracteres. Os primeiros caracteres indicam o tipo de arquivo (como diretório ou arquivo regular) e os próximos nove caracteres indicam as permissões para o proprietário, grupo e outros usuários, respectivamente.
Por exemplo, considerando drwxr-xr-x:
- O
dno início indica que é um diretório. - Os próximos três caracteres (
rwx) indicam as permissões do proprietário (read, write e execute). - Os próximos três caracteres (
r-x) indicam as permissões do grupo (read e execute). - Os últimos três caracteres (
r-x) indicam as permissões para outros usuários (read e execute).
Para modificar as permissões de um arquivo ou diretório, o comando chmod é utilizado. Ele permite adicionar ou remover permissões para o proprietário, grupo e outros usuários, conforme necessário.
Comandos Úteis
A seguir estão alguns dos comandos utilizados com maior frequência em Linux:
- ls: O comando
lsé usado para listar o conteúdo de um diretório. Quando executado sem argumentos, lista o conteúdo do diretório atual. Pode ser usado com várias opções para exibir detalhes adicionais, como permissões, propriedade e tamanho dos arquivos. - cd: O comando
cdé usado para mudar de diretório. Você pode especificar o diretório de destino como argumento para ocd, ou usarcdsem argumentos para retornar ao diretório inicial do usuário. - pwd: O comando
pwd(print working directory) é usado para imprimir o caminho completo do diretório atual em que você está trabalhando. - mkdir: O comando
mkdiré usado para criar um novo diretório. Você precisa fornecer o nome do diretório que deseja criar como argumento. - rmdir: O comando
rmdiré usado para remover um diretório vazio. Se o diretório contiver arquivos ou subdiretórios, você precisará usarrm -rpara excluí-lo recursivamente. - touch: O comando
touché usado para criar um novo arquivo vazio ou atualizar o carimbo de data/hora de um arquivo existente. - rm: O comando
rmé usado para excluir arquivos ou diretórios. Tenha cuidado ao usá-lo, pois os arquivos excluídos comrmnão são movidos para a lixeira e são permanentemente removidos do sistema. - cp: O comando
cpé usado para copiar arquivos ou diretórios de um local para outro. Você precisa fornecer o nome do arquivo/diretório de origem e o destino como argumentos. - mv: O comando
mvé usado para mover ou renomear arquivos e diretórios. Ele pode ser usado para mover arquivos de um local para outro ou para renomear um arquivo ou diretório existente. - cat: O comando
caté usado para exibir o conteúdo de um ou mais arquivos de texto na saída padrão do terminal. Também pode ser usado para concatenar vários arquivos e exibir o resultado. - grep: O comando
grepé usado para pesquisar arquivos por linhas que correspondam a um padrão especificado. É comumente usado com pipelines para filtrar a saída de outros comandos. - man: O comando
mané usado para exibir o manual de um comando específico. Ele fornece informações detalhadas sobre como usar o comando, suas opções e exemplos de uso. - chmod: O comando
chmodé usado para alterar as permissões de acesso de um arquivo ou diretório. Você pode conceder ou revogar permissões de leitura, gravação e execução para o proprietário, grupo e outros usuários. - chown: O comando
chowné usado para alterar o proprietário e/ou grupo de um arquivo ou diretório. Isso é útil para transferir a propriedade de um arquivo para outro usuário ou grupo. - sudo: O comando
sudoé usado para executar comandos com privilégios de superusuário (root). Ele permite que usuários autorizados executem tarefas que normalmente exigiriam permissões elevadas.
Detalhes interessantes para iniciantes:
- Flag -h: Em muitos comandos Unix e Linux, a flag
-hé usada como uma abreviação para "help" (ajuda). Quando usada junto com um comando ela geralmente exibe uma mensagem de ajuda ou uma breve descrição dos argumentos e opções disponíveis para esse comando específico. Esta opção é útil para obter informações rápidas sobre como usar um comando ou suas opções. - Flag --help: A flag
--helpé semelhante à flag-h, mas é uma convenção comum em muitos programas Linux para fornecer uma descrição mais detalhada das opções e argumentos disponíveis para o comando. Quando usada, geralmente exibe uma mensagem de ajuda mais abrangente, incluindo exemplos de uso e uma descrição detalhada de todas as opções disponíveis. Por exemplo, você pode usarls --helpourm --helppara obter informações detalhadas sobre como usar os comandoslserm, respectivamente.
Em sistemas Linux, as flags que começam com um único traço (-) são frequentemente chamadas de "opções de linha de comando de curto formato", enquanto as que começam com dois traços (--) são conhecidas como "opções de linha de comando de longo formato".
- Opções de linha de comando de curto formato (-):
- São frequentemente usadas para opções curtas e geralmente consistem em uma única letra.
- Podem ser agrupadas para economizar espaço na linha de comando.
- Por exemplo:
ls -l -aouls -la.
- Opções de linha de comando de longo formato (--):
- São usadas para opções mais descritivas e autoexplicativas.
- Normalmente consistem em palavras ou frases, tornando-as mais legíveis.
- Não podem ser agrupadas.
- Por exemplo:
ls --allouls --color=auto.
Ambas as formas de especificar opções são amplamente aceitas e suportadas na maioria dos programas de linha de comando em sistemas Linux. A escolha entre uma ou outra muitas vezes se resume à preferência pessoal do usuário ou às convenções específicas do programa em questão.
Conclusão e Sugestões para Aprofundamento
Neste artigo vimos alguns conceitos básicos de sistemas Linux dando ênfase a distro Kali Linux que é a preferida por profissionais de cibersegurança. Deixo por fim algumas sugestões de leituras e vídeos para se aprofundar em sistemas Linux:
- Negus, C. (2020). Linux bible, 10th Edition.
- 37 principais comandos do Linux: do básico ao avançado: https://diolinux.com.br/sistemas-operacionais/principais-comandos-do-linux-saiba-o.html
- Curso de Linux - Primeiros Passos (Curso em Vídeo): https://www.youtube.com/playlist?list=PLHz_AreHm4dlIXleu20uwPWFOSswqLYbV
- Canal Diolinux: https://www.youtube.com/@Diolinux
- Site Oficial do Linux: https://www.kernel.org/linux.html
(Incompleto)
A crescente dependência da tecnologia e a constante evolução da internet trouxeram à tona a importância da ética na segurança da informação. À medida que informações sensíveis e valiosas são armazenadas, compartilhadas e processadas digitalmente, surge a necessidade de estabelecer diretrizes éticas sólidas para garantir que esses dados sejam protegidos de maneira responsável e respeitosa.
Ética é a área do conhecimento que estuda o comportamento moral, visando compreender, criticar e justificar a moral de uma sociedade. Pode ser definida como um código moral que orienta o processo de tomada de decisão e comportamento da sociedade.
A área de segurança e informação é responsável por garantir a ética para a proteção de dados. Para isso, é importante que esta área siga as normas da LGPD (Lei Geral de Proteção de Dados), que ajudar a nortear uma empresa baseado em alguns princípios como:
- Confidencialidade: Profissionais de segurança lidam com informações pessoais, privadas ou proprietárias sensíveis que devem ser mantidas confidenciais. Garantir a confidencialidade é vital para manter a confiança entre organizações e clientes.
- **Integridade: **Profissionais de segurança devem agir com honestidade e transparência, aderindo aos mais altos padrões éticos. Isso inclui evitar conflitos de interesse, garantir relações justas e imparciais e promover uma cultura de responsabilidade.
- Responsabilidade: Os profissionais de cibersegurança têm o dever de proteger as informações e sistemas com os quais trabalham, além de relatar e abordar quaisquer vulnerabilidades ou riscos que descobrirem. Eles também devem estar preparados para enfrentar os dilemas éticos que surgem em seu ambiente de trabalho.
Dilemas éticos
Atividades de um hacker ético
As principais atividades de um hacker ético envolvem realizar análises de segurança de um sistema, identificando as possíveis vulnerabilidades para ajudar a construir "muros" mais sólidos de bloqueio a ataques cibernéticos.
Além disso, esses profissionais podem realizar testes de penetração a sistemas, simulando ataques, avaliação de vulnerabilidade do acessos aos sistemas das empresas, avaliação de riscos, entre outras funções que ajudem na proteção de dados.
Introdução à Redes
O que são Redes de Computadores?
Uma rede de computadores é um conjunto de dispositivos interconectados que são capazes de trocar informações e recursos. Esses dispositivos podem incluir computadores, servidores, dispositivos de rede (como roteadores e switches) e outros equipamentos. A finalidade principal de uma rede de computadores é permitir a comunicação entre os dispositivos, facilitando o compartilhamento de recursos, como arquivos, impressoras e conexão com a internet.
As redes de computadores podem ser classificadas de diversas maneiras, dependendo de seu tamanho, localização geográfica e tipo de tecnologia de comunicação utilizada. Elas podem variar desde pequenas redes domésticas (Local Area Network - LAN) até grandes redes corporativas ou até mesmo redes globais (Wide Area Network - WAN), como a internet. As redes podem ser cabeadas, utilizando cabos físicos para a transmissão de dados, ou sem fio, utilizando tecnologias como Wi-Fi e Bluetooth.
Internet
A Internet é uma rede de computadores que interconecta centenas de milhões de dispositivos de computação ao redor do mundo. Na verdade, o termo rede de computadores está começando a soar um tanto desatualizado, dados os muitos equipamentos não tradicionais que estão sendo ligados à Internet. A Internet pode ser descrita como uma rede de redes, onde cada rede individual pode ter sua própria estrutura e propósito, mas todas estão interligadas e podem se comunicar umas com as outras. Essas redes podem ser redes locais em empresas ou residências, data centers e até mesmo redes de dispositivos da Internet da Coisa (IoT) como geladeiras, câmeras e lâmpadas inteligentes, todas conectadas por meio de Provedores de Serviços de Internet (Internet Service Providers - ISPs). ISPs geralmente são empresas de TV a cabo ou telefonia, universidades, entre outros.
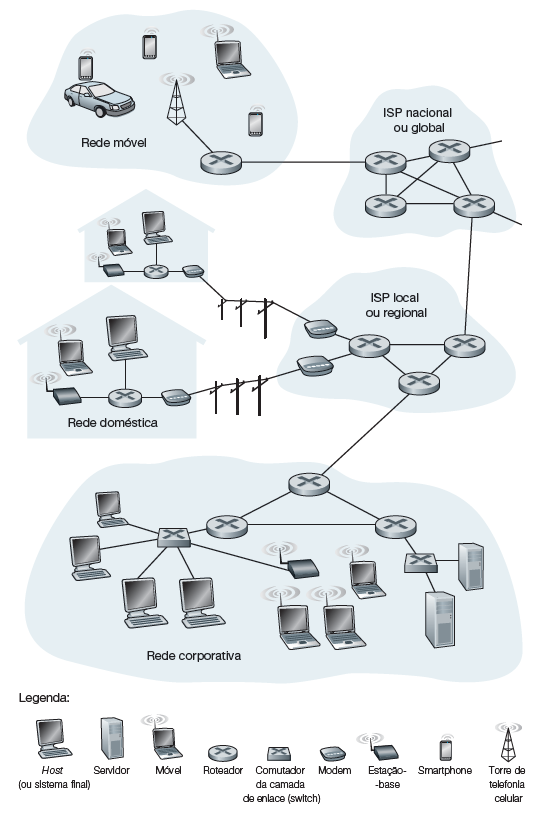
Um aspecto fundamental da Internet é a sua abertura e descentralização. Não existe uma única entidade ou organização que controle a Internet como um todo. Em vez disso, ela é composta por uma infinidade de provedores de serviços, empresas, organizações sem fins lucrativos e indivíduos que contribuem para a sua operação e desenvolvimento. Esta descentralização é parte do que torna a Internet resiliente e flexível, permitindo sua adaptação a novas tecnologias e desafios ao longo do tempo.
Além disso, a Internet é uma plataforma para uma ampla gama de serviços e aplicativos, desde comunicação e colaboração até comércio eletrônico, entretenimento e educação. Através da Internet, as pessoas podem se conectar, compartilhar ideias, acessar informações e recursos, realizar transações comerciais e muito mais, em qualquer lugar e a qualquer momento, desde que tenham acesso a uma conexão com a rede.
Infraestrutura de rede
A infraestrutura de rede é o conjunto de componentes físicos e lógicos que permitem a comunicação e o compartilhamento de recursos entre dispositivos conectados em uma rede. Esses componentes incluem dispositivos de hardware, como roteadores, switches, cabos e servidores, além de software de rede e protocolos de comunicação.
Um dos paradigmas fundamentais na infraestrutura de rede é o modelo cliente-servidor. Nesse modelo, os dispositivos na rede são geralmente divididos em dois tipos: clientes e servidores. Os clientes são dispositivos que solicitam serviços ou recursos da rede, enquanto os servidores são dispositivos que fornecem esses serviços ou recursos em resposta às solicitações dos clientes.
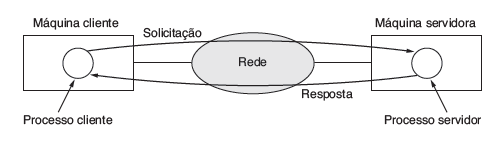
Por exemplo, em uma rede de computadores em uma empresa, os funcionários podem usar seus computadores (clientes) para acessar arquivos armazenados em um servidor de arquivos. Neste caso, o cliente envia uma solicitação ao servidor para acessar o arquivo desejado, e o servidor responde fornecendo o arquivo solicitado.
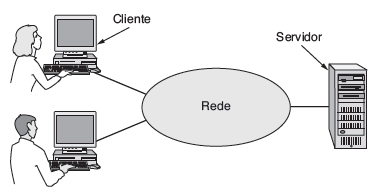
A arquitetura cliente-servidor oferece vantagens significativas em termos de escalabilidade, flexibilidade e segurança. Os servidores centralizam recursos e dados, facilitando a administração e o gerenciamento da rede. Além disso, esse modelo permite que os clientes acessem recursos compartilhados de forma eficiente e segura.
A infraestrutura de rede também pode incluir outros modelos de comunicação, como redes ponto a ponto, onde os dispositivos se comunicam diretamente entre si sem a necessidade de um servidor central. No entanto, o modelo cliente-servidor continua sendo um dos pilares fundamentais da infraestrutura de rede moderna, utilizado em uma ampla gama de cenários, desde redes empresariais até a internet em larga escala.
Pacotes
Pacotes são unidades de dados organizadas e estruturadas que são transmitidas através de redes de computadores. Eles contêm informações que são enviadas de um dispositivo para outro na rede e são essenciais para a comunicação eficiente entre os dispositivos.
Cada pacote contém dois tipos principais de informações: os dados reais que estão sendo transmitidos e os metadados que descrevem como os dados devem ser entregues. Os metadados incluem informações como o endereço de origem e destino do pacote, o tipo de protocolo usado, o número de sequência, entre outros.
Uma das principais vantagens do uso de pacotes é a capacidade de transmitir dados de forma eficiente e confiável em redes de diferentes tipos e tamanhos. Dividir os dados em pacotes menores permite que a rede lide com grandes volumes de dados de forma mais eficiente, além de possibilitar que diferentes tipos de tráfego compartilhem o mesmo meio de comunicação.
Arquitetura de Redes
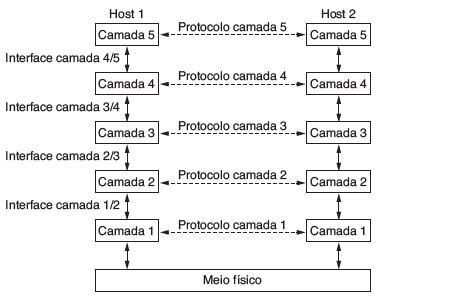
Para reduzir a complexidade de seu projeto, a maioria das redes é organizada como uma pilha de camadas (ou níveis), colocadas umas sobre as outras. O número, o nome, o conteúdo e a função de cada camada diferem de uma rede para outra. No entanto, em todas as redes o objetivo de cada camada é oferecer determinados serviços às camadas superiores, isolando essas camadas dos detalhes de implementação real desses recursos. Em certo sentido, cada camada é uma espécie de máquina virtual, oferecendo determinados serviços à camada situada acima dela.
Todas as atividades na Internet que envolvem duas ou mais entidades remotas comunicantes são governadas por um protocolo. Basicamente, um protocolo é um acordo entre as partes que se comunicam, estabelecendo como se dará a comunicação. Por exemplo, protocolos executados no hardware de dois computadores conectados fisicamente controlam o fluxo de bits no “cabo” entre as duas placas de interface de rede; protocolos de controle de congestionamento em sistemas finais controlam a taxa com que os pacotes são transmitidos entre a origem e o destino; protocolos em roteadores determinam o caminho de um pacote da origem ao destino.
Um protocolo define o formato e a ordem das mensagens trocadas entre duas ou mais entidades comunicantes, bem como as ações realizadas na transmissão e/ou no recebimento de uma mensagem ou outro evento.
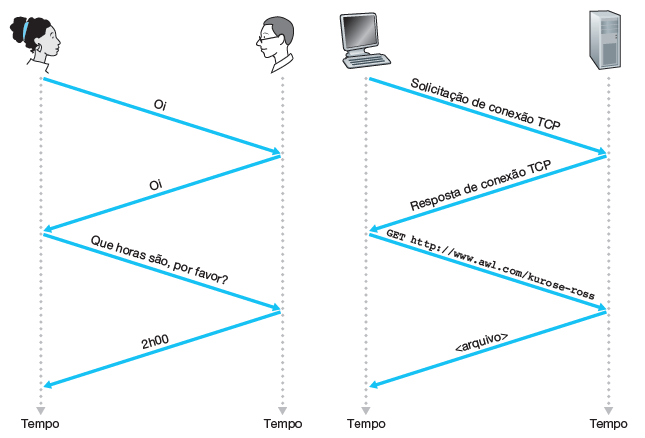
Como exemplo de um protocolo de rede de computadores com o qual você provavelmente está familiarizado, considere o que acontece quando fazemos uma requisição a um servidor Web, isto é, quando digitamos o URL de uma página Web no browser. Primeiro, o computador enviará uma mensagem de requisição de conexão ao servidor Web e aguardará uma resposta. O servidor receberá essa mensagem de requisição de conexão e retornará uma mensagem de resposta de conexão. Sabendo que agora está tudo certo para requisitar o documento da Web, o computador envia então o nome da página Web que quer buscar naquele servidor com uma mensagem GET. Por fim, o servidor retorna a página (arquivo) para o computador.
Um conjunto de camadas e protocolos é chamado arquitetura de rede. A especificação de uma arquitetura deve conter informações suficientes para permitir que um implementador desenvolva o programa ou construa o hardware de cada camada de forma que ela obedeça corretamente ao protocolo adequado. Nem os detalhes da implementação nem a especificação das interfaces pertencem à arquitetura, pois tudo fica oculto dentro das máquinas e não é visível do exterior. Nem sequer é necessário que as interfaces de todas as máquinas de uma rede sejam iguais, desde que cada uma delas possa usar todos os protocolos da maneira correta.
Modelo OSI e TCP/IP
Citamos que a maioria das redes é organizada como uma pilha de camadas para reduzir sua complexidade. Portanto, iremos destacar duas importantes arquiteturas de rede: os modelos de referência OSI e TCP/IP. Embora os protocolos associados ao modelo OSI raramente sejam usados nos dias de hoje, o modelo em si é de fato bastante geral e ainda válido, e as características descritas em cada camada ainda são muito importantes. O modelo TCP/IP tem características opostas: o modelo propriamente dito não é muito utilizado, mas os protocolos são bastante utilizados. Ambos se baseiam no conceito de uma pilha de protocolos independentes. Além disso, as camadas têm praticamente as mesmas funcionalidades. Por exemplo, em ambos os modelos estão presentes as camadas que englobam até a camada de transporte para oferecer um serviço de transporte de ponta a ponta, independente da rede, a processos que desejam se comunicar.
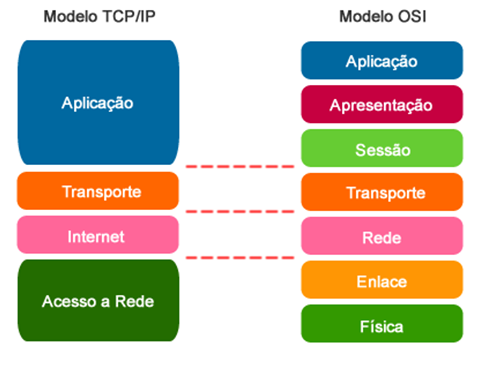
O Modelo OSI (Open Systems Interconnection) é um modelo de referência que descreve e padroniza a comunicação entre sistemas de computadores em uma rede. Desenvolvido pela International Organization for Standardization (ISO) no fim da década de 1970, o Modelo OSI é dividido em sete camadas, cada uma com funções específicas e bem definidas.
- Camada Física: A camada física lida com a transmissão física dos dados pela rede. Ela define as características elétricas, mecânicas e funcionais dos dispositivos de rede, como cabos, conectores e sinais elétricos.
- Camada de Enlace de Dados: Esta camada é responsável pela comunicação direta entre dispositivos adjacentes na rede. Ela garante uma comunicação confiável, controla o acesso ao meio físico e trata erros de transmissão.
- Camada de Rede: A camada de rede gerencia o roteamento dos dados através da rede. Ela determina o melhor caminho para os dados viajarem de um ponto a outro, utilizando algoritmos de roteamento e endereçamento.
- Camada de Transporte: A camada de transporte fornece serviços de comunicação fim a fim para os aplicativos. Ela segmenta, reagrupa e controla o fluxo de dados para garantir uma transmissão confiável e eficiente.
- Camada de Sessão: A camada de sessão estabelece, gerencia e encerra sessões de comunicação entre os aplicativos. Ela sincroniza a comunicação entre os dispositivos e lida com a recuperação de falhas de sessão.
- Camada de Apresentação: Esta camada trata da representação dos dados, garantindo que eles sejam interpretados corretamente pelos aplicativos. Ela lida com a codificação, compressão e criptografia dos dados.
- Camada de Aplicação: A camada de aplicação é a camada mais alta do modelo OSI e fornece serviços de rede diretamente aos aplicativos do usuário. Ela inclui protocolos de aplicação, como HTTP, SMTP e FTP, que permitem a comunicação e o compartilhamento de informações entre os usuários.
O Modelo TCP/IP (Transmission Control Protocol/Internet Protocol) ao contrário do Modelo OSI, que possui sete camadas, é composto por quatro camadas principais, oferecendo uma abordagem mais simplificada para a comunicação em rede.
- Camada de Interface de Rede: Também conhecida como Camada de Acesso à Rede, esta é a camada mais baixa do Modelo TCP/IP. Ela lida com a comunicação entre o dispositivo de rede e o meio físico, como cabos Ethernet ou conexões sem fio. Nesta camada, são especificados protocolos como o Ethernet e Wi-Fi.
- Camada de Internet: Esta camada é responsável pelo roteamento dos pacotes de dados através da rede. Ela utiliza endereços IP para identificar os dispositivos na rede e determina a rota para os pacotes viajarem do remetente para o destinatário. O protocolo principal nesta camada é o IP (Internet Protocol), que é o protocolo fundamental da Internet.
- Camada de Transporte: A camada de transporte fornece comunicação fim a fim entre os aplicativos na rede. Ela divide os dados em pacotes menores, se necessário, e fornece controle de fluxo e correção de erros para garantir uma transmissão confiável. Os protocolos principais nesta camada são o TCP (Transmission Control Protocol), que oferece uma comunicação confiável e orientada à conexão, e o UDP (User Datagram Protocol), que oferece uma comunicação mais rápida e não confiável.
- Camada de Aplicação: Esta é a camada mais alta do Modelo TCP/IP e engloba uma variedade de protocolos de aplicação. Ela fornece serviços de rede diretamente aos aplicativos do usuário, como navegação na web (HTTP), transferência de arquivos (FTP), envio de e-mails (SMTP) e resolução de nomes de domínio (DNS).
Principais Protocolos
Internet Protocol - IP
O Protocolo de Internet (Internet Protocol - IP) é um dos principais protocolos de comunicação das redes de computadores modernas. Ele é responsável por fornecer a identificação e o endereçamento dos dispositivos na rede, bem como o roteamento dos pacotes de dados de um ponto a outro.
O IP opera na camada de rede do Modelo OSI e utiliza um sistema de endereçamento único, conhecido como endereço IP, para identificar cada dispositivo conectado à rede. Os endereços IP são compostos por uma sequência de números binários, geralmente expressos em formato decimal separado por pontos, como por exemplo, "192.0.2.1".
Existem duas versões principais do Protocolo de Internet em uso atualmente: IPv4 e IPv6. O IPv4 é a versão original do protocolo e utiliza endereços de 32 bits, o que permite um total de aproximadamente 4,3 bilhões de endereços únicos. No entanto, devido ao crescimento explosivo da Internet, o espaço de endereçamento IPv4 está se esgotando, levando ao desenvolvimento do IPv6.
O IPv6 é uma versão mais recente do Protocolo de Internet, projetada para resolver o problema de escassez de endereços do IPv4. Ele utiliza endereços de 128 bits, proporcionando um espaço de endereçamento muito maior, teoricamente capaz de suportar um número quase ilimitado de dispositivos conectados à Internet.
TCP e UDP
Os protocolos TCP (Transmission Control Protocol) e UDP (User Datagram Protocol) são dois dos principais protocolos da camada de transporte utilizados em redes de computadores.
O TCP é um protocolo orientado à conexão e confiável, projetado para garantir que os dados sejam entregues de forma ordenada, sem erros, e com confirmação de recebimento. Ele divide os dados em segmentos e estabelece uma conexão antes de iniciar a transferência de dados. Durante a transmissão, o TCP monitora o fluxo de dados, retransmitindo pacotes perdidos ou danificados e garantindo que eles cheguem ao destino corretamente. Isso faz com que o TCP seja ideal para aplicativos que exigem uma transmissão precisa e completa dos dados, como transferências de arquivos, acesso remoto e navegação na web.
Por outro lado, o UDP é um protocolo mais simples e sem conexão, projetado para uma comunicação mais rápida e eficiente. Ele não possui mecanismos de confirmação de recebimento ou retransmissão de pacotes perdidos, o que o torna mais adequado para aplicativos que priorizam a velocidade e a eficiência em detrimento da confiabilidade absoluta. Exemplos de aplicativos que utilizam o UDP incluem streaming de vídeo e áudio, jogos online e transmissão de dados em tempo real.
Embora o TCP e o UDP tenham diferentes abordagens para a transmissão de dados, ambos são essenciais para a comunicação em redes de computadores. A escolha entre TCP e UDP depende das necessidades específicas de cada aplicativo, levando em consideração fatores como confiabilidade, velocidade, complexidade e exigências de latência. Em muitos casos, os aplicativos podem utilizar ambos os protocolos, dependendo do tipo de dado a ser transmitido e das condições da rede.
DNS
O Sistema de Nomes de Domínio (DNS - Domain Name System) é um dos componentes essenciais da infraestrutura da Internet, responsável por traduzir nomes de domínio amigáveis, como "exemplo.com", em endereços IP numéricos, como "192.0.2.1", que são utilizados pelos computadores para se comunicarem na rede.
Sem o DNS, os usuários teriam que memorizar e utilizar endereços IP numéricos para acessar sites e recursos online, o que seria impraticável. O DNS simplifica esse processo ao fornecer um sistema hierárquico de nomes de domínio que é mais fácil de ser lembrado e utilizado pelos humanos.
O funcionamento do DNS é baseado em uma estrutura distribuída de servidores de nomes, que são responsáveis por armazenar e fornecer informações sobre os nomes de domínio e seus respectivos endereços IP. Existem vários tipos de servidores de nomes, incluindo servidores de nomes raiz, servidores de nomes de domínio de alto nível (TLD), servidores de nomes autoritativos e servidores de nomes recursivos.
Quando um usuário digita um nome de domínio em seu navegador da web, o computador realiza uma consulta DNS para encontrar o endereço IP correspondente. Essa consulta é processada em várias etapas, começando com os servidores de nomes raiz, que direcionam a consulta para os servidores de nomes responsáveis pelo domínio específico. Finalmente, o endereço IP correspondente é retornado ao computador do usuário, permitindo que a comunicação ocorra.
HTTP
O Protocolo de Transferência de Hipertexto (HTTP - Hypertext Transfer Protocol) é um dos principais protocolos de comunicação utilizados na World Wide Web. Ele define as regras e convenções para a transferência de dados entre um cliente (geralmente um navegador da web) e um servidor web.
O HTTP opera no nível de aplicação do Modelo OSI e é baseado no modelo de requisição e resposta. Isso significa que, quando um cliente deseja acessar um recurso (como uma página da web) em um servidor, ele envia uma requisição HTTP ao servidor especificando o recurso desejado. O servidor, por sua vez, responde à requisição enviando os dados solicitados de volta ao cliente.
Uma das características distintivas do HTTP é o seu formato de mensagem simples, composto por um cabeçalho e, opcionalmente, um corpo de mensagem. O cabeçalho contém informações sobre a requisição ou resposta, como o método de requisição (GET, POST, PUT, DELETE), o tipo de conteúdo, o código de status e outras metainformações. O corpo da mensagem pode conter os dados propriamente ditos, como o conteúdo de uma página da web ou os parâmetros de um formulário HTML.
O HTTP é um protocolo sem estado, o que significa que cada requisição é tratada de forma independente e não mantém informações sobre requisições anteriores. Isso permite uma comunicação mais simples e eficiente entre o cliente e o servidor, mas também pode limitar a capacidade de manter o estado da sessão entre requisições.
Ao longo dos anos, o HTTP evoluiu através de diferentes versões, com melhorias de desempenho, segurança e funcionalidade. As versões mais recentes, como HTTP/1.1 e HTTP/2, introduziram recursos como compressão de dados, multiplexação de requisições e respostas, e suporte a criptografia SSL/TLS para garantir a segurança das comunicações.
Vulnerabilidades
As redes de computadores são um serviço essencial nos dias de hoje. No entanto, elas apresentam várias vulnerabilidades que podem ser exploradas por indivíduos mal-intencionados com o objetivo de obter dados confidenciais ou negar o acesso a algum serviço. Um simples exemplo de vulnerabilidade é perceptível ao se notar a facilidade de criar um pacote com qualquer endereço de origem, conteúdo de pacote e endereço de destino e transmiti-lo para a Internet, que sem nenhum problema o encaminhará ao destino. A capacidade de introduzir pacotes na Internet com um endereço de origem falso é conhecida como IP spoofing, e é uma das muitas maneiras pelas quais um usuário pode se passar por outro.
Além disso, serviços de rede, como servidores web, servidores de e-mail e servidores de arquivos, frequentemente contêm falhas de segurança que podem ser exploradas por atacantes para obter acesso não autorizado aos sistemas ou roubar informações sensíveis. Por exemplo, vulnerabilidades em servidores web podem permitir ataques de SQL injection ou cross-site scripting (XSS).
Também, Redes Wi-Fi são frequentemente alvo de ataques devido à sua natureza sem fio e à falta de segurança adequada. Atacantes podem usar técnicas como sniffing, spoofing e cracking de senhas para comprometer redes Wi-Fi e acessar dados sensíveis.
Outro ponto preocupante são os dispositivos IoT, como câmeras de segurança, termostatos inteligentes e dispositivos médicos conectados à Internet. Esses dispositivos frequentemente têm falhas de segurança que podem ser exploradas por invasores para acesso não autorizado ou controle remoto. Por exemplo, senhas padrão fracas ou falta de atualizações de segurança podem deixar os dispositivos vulneráveis a infecção por malwares construtores de botnets.
Os Ataques de Negação de Serviço (DoS) são uma forma de impedir o acesso a determinado recurso ou serviço por meio da sobrecarga de um dispositivo ou rede. Essa sobrecarga torna o serviço inacessível para usuários legítimos, causando uma negação de serviço. Por sua vez, o ataque de negação de serviço distribuído (DDoS) é realizado por uma rede de dispositivos comprometidos, as botnets anteriormente citadas, que são controlados remotamente pelo atacante. Os dispositivos na botnet podem incluir computadores, servidores, dispositivos IoT e até mesmo dispositivos móveis. O objetivo de um ataque DDoS pode variar, desde prejudicar a reputação de uma empresa até extorquir dinheiro por meio de resgate ou simplesmente interromper as operações de uma organização.
Um ataque de Man-in-the-Middle (MitM) ocorre quando um invasor intercepta e modifica comunicações entre duas partes, sem o conhecimento ou consentimento delas. O atacante se posiciona entre o remetente e o destinatário e pode ler, modificar ou até mesmo injetar novos dados na comunicação. Este tipo de ataque pode ser realizado em diferentes cenários, como redes Wi-Fi não seguras, redes com fio comprometidas, ou até mesmo em comunicações criptografadas, se o atacante tiver acesso às chaves de criptografia. Os ataques de homem-no-meio podem ser usados para capturar informações confidenciais, como senhas ou informações de cartão de crédito, realizar alterações em transações financeiras, ou até mesmo redirecionar o tráfego para sites falsos para realizar phishing.
Existem várias outras vulnerabilidades específicas de redes, portanto, é importante manter-se atualizado sobre as melhores práticas de segurança e adotar uma postura proativa na proteção das redes e dos sistemas contra esses tipos de ameaças.
Referências
TANENBAUM, Andrew S. Redes de computadores. Pearson. KUROSE, J.F. Redes de Computadores e a Internet: uma abordagem top-down. Pearson.
(Incompleto)
Red Team
Red Team é a equipe de hackers que pode planejar e definir regras para testes de ciber ataque de uma empresa. Eles podem coordenar e executar estratégias de simulação de ataque a um sistema para encontrar e identificar possíveis falhas na segurança.
Blue Team
O Blue Team se concentra em manter e melhorar a postura de segurança de informação, ao identificar falhas de segurança e corrigindo as possíveis brechas.
- Monitoramento nos sistemas de segurança
- Detecção de possíveis sistemas corrompidos
- Ações de resposta e neutralização de ciber ataques.
Forense
No campo da investigação criminal, um analista forense é um profissional responsável por aplicar metodologias para encontrar pistas deixadas na cena de um crime. Essas pistas podem ser pegadas, impressões digitais ou até mesmo o DNA encontrado no ambiente para que sirvam de análise de provas para encontrar um ou mais criminosos.
O profissional de cibersegurança forense também é conhecido por analisar "digitais" e "pegadas" deixadas por criminosos que invadiram um sistema de segurança ou base de dados, por exemplo. Este profissional aplica métodos específicos para identificas fraudes, invasões, sabotagens, entre outros crimes digitais.
GRC - Governança, risco e conformidade
Para que todas as estratégias e equipes de trabalho estejam integradas para assegurar a cibersegurança de uma empresa é preciso que haja certas normas que servem como requisitos regulatórios. É para isso que área de GRC - governança, risco e conformidade.
A área de governança, risco e conformidade trabalha com métodos estruturados para alinhar a área de T.I e segurança da informação com as metas e objetivos traçados pela empresa, visando avaliar as áreas de risco.
DevSecOps
Durante o processo de integração dos processos de desenvolvimento e operações, visando garantir a segurança dos dados sigilosos de uma empresa, é essencial a implementação de softwares específicos para cada função em uma companhia. Esse trabalho em integração e automatização desses softwares de segurança é de responsabilidade da equipe de DEvSEcOps.
DEvSecOps é a abreviação do termo em inglês "Development, Security e Operations", que significa "Desenvolvimento, Segurança e Operações". Esta área desenvolve sofrtares de segurança para agilizar o processo entre as equipes de trabalho de uma empresa.
(Incompleto)
Com o avanço da tecnologia e da interatividade digital, utilizamos cada vez mais dispositivos eletrônicos para trabalho, para o lazer e para compras online. Independente do dispositivo, acessar sites, lojas virtuais e redes sociais exigem a inclusão do cadastro de dados pessoais que, se forem expostos à terceiros, podem causar sérios prejuízos.
A segurança da informação é um campo vital, pois envolve medidas como a criptografia, autenticação de multifator, firewall, entre outros, para garantir a proteção e segurança de dados sensíveis dos usuários. Porém, caso haja alguma brecha nesse sistema, pode ser uma porta aberta para o ataque de hackers.
Hackers
No sentido mais amplo, um hacker é alguém que entende profundamente os sistemas computacionais e as redes e usa esse conhecimento para explorar, modificar ou contornar as limitações dos sistemas. A intenção do hacker pode variar de acordo com suas motivações, que podem incluir aprendizado, melhoria de sistemas, segurança cibernética ética ou atividades maliciosas. Capazes de criar softwares e sistemas complexos, com o passar do termo, o termo hacker foi atribuído àqueles que usam suas habilidades para atividades ilegais e cometer crimes, como a invasão se sistemas e o roubo de dados e informações. No entanto, isso não é verdade e na realidade existem diferentes tipos de hackers, como explicado a seguir:
Tipos de hackers
Os hacker desempenham diferentes e complexos papeis no mundo da tecnologia. Não existem apenas aqueles que visam o benefício próprio, cometendo crimes e ataque cibernéticos à empresas. O termo hacker também pode ser associado a profissionais que usam suas habilidades para identificar as vulnerabilidades de segurança em sistemas e redes.
Nesse sentido, é comum separar as categorias de hackers em 3 tipos: White Hat Hackers, Grey Hat Hackers e Black Hat Hackers.
-
Hacker White Hat (Ético):
- São hackers éticos e legais que utilizam suas habilidades para proteger sistemas. Trabalham como profissionais de segurança, testando sistemas em busca de vulnerabilidades e ajudando a corrigi-las antes que possam ser exploradas por criminosos.
-
Hacker Black Hat (Malicioso):
- Agem de maneira maliciosa, explorando vulnerabilidades para ganho pessoal ou causando danos a sistemas. Criminosos cibernéticos, crackers e invasores de sistemas muitas vezes se enquadram nessa categoria.
-
Hacker Grey Hat (Neutro):
- Essa categoria é um meio-termo entre os hackers éticos e maliciosos. Um hacker grey hat pode explorar sistemas sem permissão, mas sem intenções maliciosas. Às vezes, revelam as vulnerabilidades que descobrem, mas nem sempre obtêm permissão para suas atividades.
Outras subcategorias são destacas a seguir:
-
Hacker Hacktivista:
- São hackers que realizam atividades cibernéticas para promover causas sociais ou políticas. Suas ações muitas vezes envolvem invadir sistemas como forma de protesto ou para chamar a atenção para determinadas questões.
-
Hacker Script Kiddie:
- Refere-se a indivíduos sem habilidades técnicas significativas que utilizam ferramentas ou scripts prontos para uso para realizar ataques. Geralmente, eles não entendem profundamente o que estão fazendo.
-
Hacker Phreaker:
- Originalmente, um termo utilizado para descrever aqueles que exploram e manipulam sistemas telefônicos. Atualmente, o termo pode se estender para hackers que se concentram em explorar e manipular sistemas de comunicação mais amplos.
-
Hacker Social Engineering:
- Embora não seja estritamente técnico, este tipo de hacker explora a natureza humana para obter informações confidenciais. Usam técnicas de persuasão e manipulação para enganar as pessoas e obter acesso não autorizado a sistemas.
-
Hacker de Hardware:
- Concentra-se em explorar vulnerabilidades em dispositivos físicos, circuitos eletrônicos e outros componentes de hardware.
É importante destacar que, dependendo do contexto, o termo "hacker" pode ser utilizado de maneira positiva ou negativa. Muitos hackers desempenham papéis cruciais na segurança cibernética, enquanto hackers maliciosos (crackers) representam uma ameaça à segurança digital.
O protocolo HTTP
Por Álvaro L., Lucas Albano e Thiago Felipe
O Protocolo de Transferência de Hipertexto, abreviado como HTTP (do inglês, Hypertext Transfer Protocol), é a base da comunicação na World Wide Web (WWW). Desde sua criação por Tim Berners-Lee na década de 1990, o HTTP tem sido essencial para a troca de informações entre clientes, como navegadores web, e servidores. Neste artigo, vamos explorar detalhadamente o que é o protocolo HTTP, como ele funciona, suas etapas de comunicação, os tipos de requisições, métodos e os códigos de status.
O que é o Protocolo HTTP?
O Protocolo HTTP é um protocolo da camada de aplicação utilizado para transferir documentos de hipermídia, como o HTML. Ele opera no modelo cliente-servidor, onde um cliente (geralmente um navegador web) faz requisições a um servidor para acessar recursos, como páginas da web, imagens ou vídeos, através de URLs (Uniform Resource Locators). É também um protocolo sem estado ou stateless protocol, que significa que o servidor não mantem nenhum dado entre duas requisições (state). Apesar de ser frequentemente baseado em uma camada TCP/IP, pode ser utilizado em qualquer camada de transporte confiável, ou seja, um protocolo que não perde mensagens silenciosamente como o UDP.
Mas e o HTTPS?
O HTTPS (Hypertext Transfer Protocol Secure) é uma atualização do protocolo HTTP original que introduz camadas de segurança. Anteriormente, o modelo HTTP mantinha a conexão entre cliente e servidor como pacotes de bytes abertos, portanto qualquer um que conseguisse interceptar esse tráfego seria capaz de acessar informações sensíveis do usuário que poderiam estar nesse pacote. Pensando nisso, foi criado o modelo HTTPS, que emprega criptografia SSL/TLS para proteger a integridade e a privacidade das informações durante a comunicação entre o navegador do usuário e o servidor web.
O modelo SSL/TLS consiste na forma de criptografia utilizada junto com o HTTP atualmente, que foi primeiramente implementado com o SSL(Secure Sockets Layer), criado pela empresa Netscape. Nesse sentido, apesar de o modelo funcionar muito bem, ele possuía algumas falhas de segurança, além disso órgãos reguladores relacionados à internet, principalmente dos EUA, ficaram preocupados com a exclusividade que a Netscape tinha com relação a esse modelo de criptografia, uma vez que se eles cessassem seus serviços de alguma maneira, todo o tráfico HTTPS também pararia imediatamente. Nesse sentido, com a intenção de não se tornar refém de uma empresa privada, foi criado o protocolo TLS(Transport Layer Security), tendo como ponto de partida o SSL e resolvendo os problemas de segurança que seu antecessor possuía.
O protocolo TLS atual funciona com uma mistura de criptografia utilizando chaves simétricas e assimétricas. Primeiramente, quando o cliente tenta estabelecer o primeiro contato com o servidor, ele utiliza da chave de criptografia pública do servidor para criptografar uma mensagem contendo uma chave simétrica, o servidor utiliza sua chave privada para descriptografar essa mensagem e assim, receber a chave que estava contida nela. A partir desse momento, o servidor e o cliente começam a se comunicar utilizando essa chave simétrica, esse método evita que a chave seja interceptada por alguém mal-intencionado e permite a comunicação por criptografia simétrica, que é mais rápida e, portanto, melhora a performance da comunicação entre as duas partes.
Funcionamento e Estrutura do HTTP
O HTTP opera em um modelo de solicitação-resposta (request-response), seguindo várias etapas de comunicação:
- Estabelecimento da Conexão: O cliente inicia a comunicação estabelecendo uma conexão TCP/IP com o servidor na porta padrão 80 para HTTP ou na porta 443 para HTTPS.
- Solicitação (Request): O cliente envia uma mensagem de requisição HTTP contendo informações como o método da requisição (GET, POST, etc.), a URL do recurso desejado, cabeçalhos de requisição e, opcionalmente, o corpo da requisição com dados adicionais.
- Processamento da Requisição: O servidor recebe a requisição, interpreta os dados e determina o que deve ser feito.
- Resposta (Response): O servidor envia uma mensagem de resposta HTTP de volta ao cliente contendo o código de status da resposta (200, 302, 404, etc.), os cabeçalhos de resposta e, opcionalmente, o corpo da resposta com os dados solicitados pelo cliente.
- Fechamento da Conexão: Após completar a transmissão, a conexão TCP pode ser encerrada, a menos que seja mantida aberta para futuras solicitações (através do cabeçalho
Connection: keep-alive).
Pacotes HTTP
Um pacote HTTP possui dois tipos principais de cabeçalhos: o cabeçalho de solicitação (Request Header), enviado pelo cliente para o servidor, e o cabeçalho de resposta (Response Header), enviado pelo servidor de volta para o cliente.
Cabeçalho de Solicitação (Request Header):
Método URI Versão_HTTP
Cabeçalho_1: Valor_1
Cabeçalho_2: Valor_2
...
Cabeçalho_N: Valor_N
Corpo_da_Solicitação (Opcional)
- Método: Indica a ação que o cliente deseja realizar no recurso identificado pelo URI. Exemplos comuns incluem GET, POST, PUT, DELETE, etc.
- URI: Uniform Resource Identifier que identifica o recurso solicitado.
- Versão HTTP: Versão do protocolo HTTP sendo usada, como HTTP/1.1.
- Cabeçalhos: São pares chave-valor que fornecem informações adicionais sobre a solicitação. Podem incluir informações sobre o cliente, preferências de conteúdo, formatos aceitos, cookies, entre outros.
- Corpo da Solicitação: Opcionalmente, a solicitação pode incluir um corpo, contendo os dados a serem enviados ao servidor, como no caso de solicitações POST.
Nem todos os cabeçalhos exibidos em uma requisição são cabeçalhos de requisição. Por exemplo, o
Content-lengthexibido em uma requisição POST é na realidade uma entity header, que referencia o tamanho do corpo da mensagem de requisição. Porém, esses cabeçalhos de entidade muitas vezes são chamados de cabeçalhos de requisição.
Exemplo de Request Header:
GET /home.html HTTP/1.1
Host: developer.mozilla.org
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.9; rv:50.0) Gecko/20100101 Firefox/50.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: en-US,en;q=0.5
Accept-Encoding: gzip, deflate, br
Referer: https://developer.mozilla.org/testpage.html
Connection: keep-alive
Upgrade-Insecure-Requests: 1
If-Modified-Since: Mon, 18 Jul 2016 02:36:04 GMT
If-None-Match: "c561c68d0ba92bbeb8b0fff2a9199f722e3a621a"
Cache-Control: max-age=0
Entity Headers Comuns:
- Content-Type: Indica o tipo de mídia do corpo da entidade, como text/html, application/json, image/jpeg, etc.
- Content-Length: Indica o tamanho do corpo da entidade em bytes.
- Content-Encoding: Indica a codificação aplicada ao corpo da entidade, como gzip, deflate, br, etc.
- Content-Language: Indica o idioma natural ou idiomas do conteúdo no corpo da entidade.
- Content-Disposition: Especifica a forma como o conteúdo deve ser apresentado ao usuário, por exemplo, inline (dentro da página) ou attachment (como um download).
- ETag: Uma etiqueta de entidade exclusiva, geralmente usada para verificação de condições de atualização usando cabeçalhos de solicitação If-Match ou If-None-Match.
- Last-Modified: Indica a data e hora em que a entidade foi modificada pela última vez.
- Expires: Indica a data e hora de expiração da entidade, após a qual ela é considerada obsoleta.
- Cache-Control: Controla o comportamento de armazenamento em cache de entidades em caches intermediários.
- Pragma: Usado para fornecer diretivas de controle de cache para compatibilidade com versões mais antigas do HTTP.
- Allow: Especifica os métodos HTTP permitidos em uma entidade.
Cabeçalho de Resposta (Response Header):
Versão_HTTP Código_de_Status Razão
Cabeçalho_1: Valor_1
Cabeçalho_2: Valor_2
...
Cabeçalho_N: Valor_N
Corpo_da_Resposta (Opcional)
- Versão HTTP: Versão do protocolo HTTP sendo usada, como HTTP/1.1.
- Código de Status: Indica o resultado do processamento da solicitação pelo servidor, como 200 para sucesso, 404 para recurso não encontrado, 500 para erro interno do servidor, etc.
- Razão: Uma breve descrição textual do código de status.
- Cabeçalhos: Assim como no cabeçalho de solicitação, os cabeçalhos de resposta são pares chave-valor que fornecem informações adicionais sobre a resposta enviada pelo servidor.
- Corpo da Resposta: Opcionalmente, a resposta pode incluir um corpo, contendo os dados solicitados pelo cliente, como no caso de solicitações GET bem-sucedidas.
Requisições HTTP:
Existem nove tipos de métodos HTTP que podem ser utilizados em uma requisição, são eles:
- GET: Solicita dados de um recurso específico
- POST: Submete dados para serem processados por um recurso identificado pela URL.
- PUT: Substitui todas as representações atuais do recurso de destino com o carregado no corpo da requisição.
- DELETE: Remove o recurso especificado.
- PATCH: Aplica modificações parciais a um recurso.
- HEAD: Solicita apenas os cabeçalhos de resposta, sem o corpo da resposta.
- TRACE: Ecoa o pedido, de maneira que o cliente possa saber o que os servidores intermediários estão mudando em seu pedido.
- OPTIONS: Recupera os métodos HTTP que o servidor aceita.
- CONNECT: Serve para uso com um proxy que possa se tornar um túnel SSL e TLS (um túnel pode ser usado, por exemplo, para criar uma conexão segura).
Status HTTP:
Após receber uma requisição, o servidor responde com um código de status HTTP, que indica o resultado da operação. Grupos de status HTTP:
- 1xx: Informacional - Indica que a requisição foi recebida e está sendo processada.
- 2xx: Sucesso - Indica que a requisição foi bem-sucedida.
- 3xx: Redirecionamento - Indica que é necessário tomar uma ação adicional para completar a requisição.
- 4xx: Erro do Cliente - Indica que ocorreu um erro na requisição do cliente.
- 5xx: Erro do Servidor - Indica que ocorreu um erro no servidor enquanto processava a requisição.
Códigos de status mais comuns:
-
200 OK: Indica uma solicitação HTTP bem-sucedida. A resposta inclui o conteúdo solicitado, dependendo do método de solicitação (GET, PUT, POST, etc.).
-
201 Created: Confirma que a solicitação foi bem-sucedida e resultou na criação de um novo recurso.
-
204 No Content: O servidor atendeu à solicitação, mas não há conteúdo para retornar. Geralmente usado para solicitações que não exigem resposta, como exclusões.
-
205 Reset Content: Diz ao agente do usuário para redefinir o documento que enviou esta solicitação.
-
300 Multiple Choices: A solicitação tem mais de uma resposta possível. O agente do usuário ou usuário deve escolher um deles. (Não há uma maneira padronizada de escolher uma das respostas, mas links HTML para as possibilidades são recomendados para que o usuário possa escolher).
-
301 Moved Permanently: A URL do recurso solicitado foi alterada permanentemente. A nova URL é fornecida na resposta.
-
302 Found: Este código de resposta significa que o URI do recurso solicitado foi alterado temporariamente. Outras alterações no URI podem ser feitas no futuro. Portanto, esta mesma URI deve ser utilizada pelo cliente em requisições futuras.
-
304 Not Modified: Usado para cache de navegador. Indica que a versão em cache do recurso ainda é válida e pode ser usada.
-
400 Bad Request: O servidor não consegue entender ou processar a solicitação devido a um erro do cliente, como dados ausentes ou formatação inválida.
-
401 Unauthorized: A autenticação é necessária para acessar o recurso, mas falhou ou não foi fornecida.
-
403 Forbidden: O servidor se recusa a aceitar a solicitação, mesmo que seja válida. Geralmente por falta de permissão.
-
404 Not Found: Indica que o recurso solicitado não foi encontrado no servidor.
-
409 Conflict: A solicitação entra em conflito com o estado atual do recurso, geralmente devido a atualizações simultâneas.
-
410 Gone: O recurso solicitado não está mais disponível e não estará novamente.
-
500 Internal Server Error: Indica um problema inesperado no servidor que impede o atendimento da solicitação. Geralmente requer investigação por parte dos desenvolvedores para identificar a causa.
-
501 Not Implemented: O método da requisição não é suportado pelo servidor e não pode ser manipulado.
Cookies
HTTP Cookies são pequenos arquivos de texto armazenados no dispositivo do usuário pelo navegador da web. Eles são usados para armazenar informações específicas sobre a atividade do usuário em um determinado site. Os cookies desempenham um papel fundamental na personalização da experiência do usuário na web, permitindo que os sites se lembrem das preferências e do histórico de navegação dos usuários.
Funcionamento dos cookies
Quando um usuário visita um site, o navegador envia uma solicitação HTTP para o servidor web. Esta solicitação inclui informações sobre o navegador, o dispositivo e outras informações relevantes. O servidor responde à solicitação enviando não apenas o conteúdo da página solicitada, mas também instruções sobre como o navegador deve se comportar. Isso inclui a definição de cookies.
Quando o navegador recebe a resposta do servidor, ele armazena os cookies no dispositivo do usuário. Os cookies geralmente consistem em pares de chave-valor e podem conter informações como preferências de idioma, informações de login, itens no carrinho de compras, etc. Em solicitações subsequentes para o mesmo site, o navegador envia os cookies relevantes de volta para o servidor junto com a solicitação HTTP. Isso permite que o servidor acesse as informações armazenadas nos cookies e personalize a experiência do usuário de acordo. O servidor processa os cookies recebidos junto com a solicitação e utiliza as informações contidas neles para personalizar a resposta. Por exemplo, se um usuário está logado, o servidor pode fornecer acesso a áreas restritas do site.
Os cookies podem ser atualizados, modificados ou excluídos pelo servidor a qualquer momento. Eles também podem ter uma data de expiração, após a qual são automaticamente removidos pelo navegador.
Os cookies são amplamente utilizados na web para uma variedade de fins, incluindo rastreamento de sessões de usuários, personalização de conteúdo, armazenamento de preferências do usuário e muito mais. No entanto, é importante observar que os cookies também podem levantar preocupações com a privacidade do usuário, especialmente quando são usados para rastrear o comportamento do usuário sem seu consentimento explícito.
Principais vulnerabilidades do protocolo HTTP:
- Falta de Criptografia:
O HTTP transmite dados em texto simples, o que significa que qualquer pessoa com acesso ao tráfego de rede pode interceptar e ler as informações transmitidas entre o cliente e o servidor. Isso torna o HTTP suscetível a ataques de interceptação de dados, como o sniffing de pacotes, onde os invasores podem capturar e analisar o tráfego de rede em busca de dados sensíveis, como credenciais de login e informações financeiras.
- Ataques Man-in-the-Middle (MITM):
Os ataques MITM são uma ameaça significativa ao protocolo HTTP, onde os invasores interceptam o tráfego de rede entre o cliente e o servidor para realizar atividades maliciosas, como a modificação de dados transmitidos, o roubo de informações confidenciais e a injeção de código malicioso em páginas da web. Como o HTTP não possui criptografia embutida, os ataques MITM podem ser facilmente realizados, comprometendo a segurança da informação online.
- Ataques de Injeção de Conteúdo:
Devido à falta de validação adequada de entrada de dados, o HTTP é vulnerável a ataques de injeção de conteúdo, como SQL Injection e Cross-Site Scripting (XSS). Os atacantes podem explorar essas vulnerabilidades para inserir código malicioso nos dados transmitidos via HTTP, comprometendo a segurança do aplicativo web e permitindo a execução de comandos não autorizados no servidor.
- Replay Attacks:
Sem controle de estado embutido, o HTTP está suscetível a ataques de repetição, onde os invasores capturam e retransmitem solicitações HTTP válidas para realizar ações não autorizadas no servidor ou comprometer a integridade dos dados transmitidos. Os replay attacks representam uma ameaça significativa à segurança do HTTP, especialmente em cenários onde a autenticação do usuário é realizada via tokens de sessão não criptografados.
- Exposição de Dados Sensíveis:
Devido à transmissão de dados sensíveis via URL no HTTP GET, há o risco de exposição de informações confidenciais nos logs do servidor, caches de proxy e histórico do navegador. Isso pode incluir senhas, tokens de autenticação, informações financeiras e outros dados privados, tornando os usuários vulneráveis a ataques de espionagem e roubo de identidade.
- Cookies Inseguros:
Os cookies são frequentemente usados para rastrear a sessão do usuário em sites. No entanto, quando transmitidos sem criptografia, os cookies podem ser interceptados e manipulados por atacantes para assumir a identidade de um usuário legítimo, realizar sessões hijacking (sequestro de navegador, que é a modificação não autorizada das configurações de um navegador) e acessar informações confidenciais.
Mitigação das vulnerabilidades do HTTP:
Para mitigar as vulnerabilidades do HTTP, são recomendadas as seguintes medidas de segurança:
- Implementação do HTTPS para criptografar o tráfego de rede.
- Uso de firewalls de aplicativos da web (WAFs) para proteger contra ataques de injeção de conteúdo e outros ataques de aplicativos da web.
- Validação rigorosa de entrada de dados para prevenir ataques de injeção.
- Autenticação de dois fatores para proteger contra ataques de replay e roubo de credenciais.
- Criptografia de cookies para proteger informações sensíveis durante a transmissão.
Conclusão:
O Protocolo HTTP é um dos principais protocolos da internet, sendo fundamental para seu funcionamento. Ao entender suas etapas de comunicação, os tipos de requisições e respostas, métodos, códigos de status, sua estrutura e as vulnerabilidades, os desenvolvedores são capacitados a criar aplicações web mais seguras. Além disso, entender o HTTP é indispensável para profissionais de segurança da informação, como pentesters, pois é o procolo que dita a interação com aplicações web.
Materiais complementares:
- https://www.alura.com.br/artigos/http
- https://youtu.be/CXzbUwK6lc8?si=y49BSdsCY4uwidrZ
- https://developer.mozilla.org/pt-BR/docs/Web/HTTP
- https://en.wikipedia.org/wiki/HTTP_cookie
Estrutura de uma URL
Autor: Lucas Albano
As URLs (Uniform Resource Locators) são fundamentais para a navegação na web. Uma compreensão básica de sua estrutura é crucial para qualquer pessoa utilize a internet e indispensável para profissionais de segurança da informação.
Componentes de uma URL
Uma URL típica é composta por vários componentes:
Esquema (Scheme)
O esquema é o protocolo que indica como o recurso deve ser acessado. Alguns dos esquemas mais comuns incluem:
- HTTP: para recursos web não seguros.
- HTTPS: para recursos web seguros que usam criptografia SSL/TLS.
- FTP: para acesso a servidores FTP.
- File: para arquivos locais no sistema de arquivos.
Nome de Usuário e Senha (Username e Password)
Esses componentes são opcionais e geralmente são usados apenas para autenticação em determinados recursos protegidos por senha. Eles são separados do restante da URL por dois pontos (:).
Host e Porta
O host é o endereço do servidor onde o recurso está localizado. Pode ser um domínio, como "www.exemplo.com", ou um endereço IP. Opcionalmente, uma URL pode especificar uma porta onde o recurso está disponível, separada do host por dois pontos (:). Se a porta não for especificada, será utilizada a porta padrão para o esquema fornecido.
Caminho (Path)
O caminho indica o local específico do recurso no servidor. Ele começa após o nome do host e pode incluir vários diretórios e subdiretórios, além do próprio nome do arquivo.
Consulta (Query)
A parte de consulta de uma URL é usada para enviar parâmetros adicionais para o servidor. Ela começa com um ponto de interrogação (?) e consiste em pares de chave-valor separados por e comercial (&). Por exemplo, em "?id=123&nome=exemplo", "id" e "nome" são os parâmetros da consulta, com os valores "123" e "exemplo", respectivamente.
Fragmento (Fragment)
O fragmento identifica uma parte específica do recurso. Ele começa com uma cerquilha (#) e geralmente é usado em páginas da web para direcionar o navegador para uma seção específica da página.
Exemplo de URL Completa
Segue um exemplo de uma URL completa com todos os componentes mencionados:
https://username:password@www.exemplo.com:8080/pasta/recurso.html?id=123&nome=exemplo#secao
Neste exemplo:
- Esquema: HTTPS
- Nome de Usuário e Senha: username e password
- Host: www.exemplo.com
- Porta: 8080
- Caminho: /pasta/recurso.html
- Consulta: id=123&nome=exemplo
- Fragmento: secao
IDOR - Insecure direct object references
Autor: Lucas Albano
Insecure direct object references (IDOR - Referências diretas inseguras a objetos) são um tipo de vulnerabilidade de controle de acesso que ocorre quando um aplicativo permite que usuários acessem objetos diretamente, sem validar se possuem permissão para isso. O termo IDOR foi popularizado pelo OWASP Top Ten em 2007, mas representa apenas um exemplo de falhas comuns de controle de acesso.
Causas
A vulnerabilidade IDOR ocorre quando um aplicativo confia nas entradas fornecidas pelo usuário para acessar objetos sem verificar se o usuário tem permissão para isso. Por exemplo, em um sistema de compras online, uma URL como https://exemplo.com/pedido?id=123 pode permitir que um atacante modifique o ID do pedido na URL para acessar informações de outros usuários, caso o aplicativo não valide adequadamente as permissões de acesso.
Mais Exemplos
Por exemplo, ao acessar um perfil de usuário a aplicação web pode gerar uma URL como https://example.org/users/123. O 123 na URL é uma referência direta ao registro do usuário no banco de dados, geralmente representado pela chave primária. Caso um atacante altere esse número para 124 e obtiver acesso às informações de outro usuário, o aplicativo está vulnerável à Insecure Direct Object Reference. Isso acontece porque o aplicativo não verificou corretamente se o usuário tinha permissão para visualizar os dados do usuário 124 antes de exibi-los.
Em alguns casos, o identificador pode não estar na URL, mas sim no corpo do POST, conforme exemplo a seguir:
<form action="/update_profile" método="post">
<!-- Outros campos para atualização de nome, email, etc. -->
<input type="hidden" name="user_id" value="12345">
<button type="submit">Atualizar perfil</button>
</form>
Neste exemplo, o aplicativo permite que os usuários atualizem seus perfis enviando um formulário com o ID do usuário em um campo oculto. Se o aplicativo não realizar o controle de acesso adequado no lado do servidor, os atacantes podem manipular o campo “user_id” para modificar perfis de outros usuários sem autorização.
Mitigação
Para mitigar um IDOR, é crucial implementar verificações de controle de acesso para cada objeto que os usuários tentem acessar. Os usuários devem ter acesso apenas aos recursos que precisam para realizar suas tarefas. Limitar o acesso aos recursos sensíveis ajuda a reduzir a superfície de ataque. Além disso, podem ser utilizados identificadores complexos como medida de defesa adicional, mas o controle de acesso é crucial mesmo com esses identificadores.
Se possível, evite expor identificadores em URLs e corpos POST. Em vez disso, determine o usuário atualmente autenticado a partir das informações da sessão. Ao utilizar várias etapas de fluxo, passe identificadores na sessão para evitar adulterações.
Referências
- OWASP Cheat Sheet Series: Insecure Direct Object Reference Prevention Cheat Sheet
- PortSwigger: Insecure direct object references (IDOR)
- Varonis: O que é IDOR (Insecure Direct Object Reference)?
SQL Injection (SQLi)
Neste artigo, exploraremos os fundamentos do SQL, como funcionam as consultas SQL, e em seguida os detalhes de SQL Injection. Abordaremos como essa vulnerabilidade é identificada, os diferentes tipos de ataques possíveis, e algumas estratégias simples para mitigá-la e proteger aplicações web contra potenciais explorações.
Primeiro, o que é SQL?
SQL (Structured Query Language) é uma linguagem padrão usada para gerenciar bancos de dados relacionais. Foi originalmente desenvolvida pela IBM nos anos 70 e desde então se tornou a linguagem de fato para interagir com sistemas de gerenciamento de banco de dados (SGBDs) como MySQL, PostgreSQL, SQL Server, Oracle, entre outros.
A principal função do SQL é permitir que os desenvolvedores e administradores de banco de dados possam realizar operações como consultas (queries), inserções, atualizações e exclusões de dados em um banco de dados. Além disso, o SQL também oferece recursos para criar e modificar estruturas de banco de dados, como tabelas, índices, procedimentos armazenados e funções.
A linguagem SQL é estruturada em diferentes partes, incluindo:
-
DDL (Data Definition Language): Usada para definir a estrutura e esquema dos objetos no banco de dados, como CREATE (criação), ALTER (alteração) e DROP (exclusão).
-
DML (Data Manipulation Language): Usada para manipular os dados dentro dos objetos do banco de dados, como INSERT (inserção), SELECT (seleção), UPDATE (atualização) e DELETE (exclusão).
-
DCL (Data Control Language): Usada para gerenciar as permissões e acessos aos dados, como GRANT (concessão de permissões) e REVOKE (revogação de permissões).
Estrutura de uma Query
Uma query SQL possui uma estrutura básica que varia dependendo da operação que você deseja realizar (consulta, inserção, atualização, exclusão) e das cláusulas específicas que você precisa aplicar para filtrar ou manipular os dados. Vamos detalhar a estrutura básica de uma consulta (SELECT), que é uma das operações mais comuns em SQL:
Estrutura básica de uma consulta SQL (SELECT):
-
SELECT: Indica quais colunas ou expressões serão retornadas pela consulta. Você pode selecionar todas as colunas usando
*ou especificar colunas específicas separadas por vírgula.Exemplo:
SELECT coluna1, coluna2, coluna3 FROM tabela;Neste exemplo,
coluna1,coluna2ecoluna3são colunas específicas da tabelatabela. -
FROM: Especifica a tabela ou tabelas das quais os dados serão recuperados. Pode-se consultar uma ou várias tabelas simultaneamente usando junções (JOINs).
Exemplo:
SELECT * FROM clientes;Aqui,
clientesé o nome da tabela da qual estamos recuperando todas as colunas (*). -
WHERE (opcional): Permite filtrar os resultados com base em uma condição específica. A condição pode ser qualquer expressão que avalie como verdadeira, como comparações, operadores lógicos, funções, etc.
Exemplo:
SELECT * FROM pedidos WHERE valor_total > 1000;Neste caso, estamos selecionando todos os pedidos da tabela
pedidosonde ovalor_totalé maior que 1000. -
ORDER BY (opcional): Define a ordem dos resultados com base em uma ou mais colunas. Por padrão, a ordenação é crescente (ASC), mas você pode especificar descendente (DESC) se necessário.
Exemplo:
SELECT * FROM produtos ORDER BY preco DESC;Aqui, estamos selecionando todos os produtos da tabela
produtosordenados pelo preço em ordem decrescente. -
GROUP BY (opcional): Agrupa os resultados com base em uma ou mais colunas. É comumente usado com funções de agregação, como SUM, AVG, COUNT, etc.
Exemplo:
SELECT departamento, COUNT(*) as num_funcionarios FROM funcionarios GROUP BY departamento;Este exemplo conta o número de funcionários em cada departamento da tabela
funcionarios. -
HAVING (opcional): É usado em conjunto com GROUP BY para filtrar os resultados de grupos específicos baseados em condições.
Exemplo:
SELECT departamento, AVG(salario) as media_salario FROM funcionarios GROUP BY departamento HAVING AVG(salario) > 5000;Aqui, estamos selecionando departamentos onde a média de salário dos funcionários é superior a 5000.
Exemplo completo:
SELECT nome, idade, cidade
FROM usuarios
WHERE cidade = 'São Paulo'
ORDER BY idade DESC;
Neste exemplo:
SELECT nome, idade, cidade: Seleciona as colunasnome,idadeecidade.FROM usuarios: Indica que os dados serão buscados na tabelausuarios.WHERE cidade = 'São Paulo': Filtra os resultados para incluir apenas aqueles onde a colunacidadeé igual a'São Paulo'.ORDER BY idade DESC: Ordena os resultados com base na colunaidade, em ordem decrescente.
Essa estrutura básica pode ser expandida com outras cláusulas SQL dependendo das necessidades específicas da consulta, mas esses são os elementos essenciais para construir e entender uma query SQL simples de consulta.
ORMs(Object Relational Mapping):
ORMs são frameworks de desenvolvimento que intermediam o processo de consulta no banco de dados transformando tabelas SQL em Objetos e vice-versa, dessa forma, os desenvolvedores não precisem trabalhar diretamente com SQL. Essa alternativa além de acarretar em mais produtividade, também evita vulnerabilidades SQL pois permite uma filtragem pela aplicação antes que ela crie a query. Dentre os principais Frameworks estão:
- Prisma(Javascript e Typescript)
- PonyORM(Python)
- SQLAlchemy(Python)
- Entity Framework(.NET)
SQL Injection
O SQL Injection (SQLi) é uma vulnerabilidade web que permite que um invasor interfira nas consultas que um aplicativo faz em seu banco de dados. Isso pode permitir que um invasor visualize dados que normalmente não deveria conseguir acessar. Isso pode incluir dados que pertencem a outros usuários ou quaisquer outros dados que o aplicativo possa acessar. Em muitos casos, um invasor pode modificar ou excluir esses dados, causando alterações persistentes no conteúdo ou no comportamento do aplicativo.
Em algumas situações, um invasor pode escalar um ataque de SQL Injection para comprometer o servidor subjacente ou outra infraestrutura de back-end. Também pode possibilitar a realização de ataques de negação de serviço (DoS).
Como funciona o SQL Injection?
SQL Injection explora a maneira como os dados são manipulados em uma aplicação web que utiliza consultas SQL para interagir com seu banco de dados. Aqui estão os passos básicos de como um ataque de SQL Injection pode ser realizado:
-
Identificação da Vulnerabilidade: Um invasor identifica uma entrada de usuário que não é adequadamente validada ou sanitizada antes de ser incluída em uma consulta SQL.
-
Inserção de código malicioso: O invasor insere código SQL malicioso na entrada, aproveitando-se da falha de segurança. Isso geralmente é feito através de campos de formulário, parâmetros de URL, cookies ou cabeçalhos HTTP.
-
Execução da Instrução Maliciosa: Quando o aplicativo web executa a consulta SQL, o código malicioso também é executado, causando efeitos indesejados.
Exemplo de SQL Injection:
Suponha que um aplicativo de login tenha uma consulta SQL para verificar as credenciais do usuário:
SELECT * FROM usuarios WHERE usuario = 'usuario_digitado' AND senha = 'senha_digitada';
Um invasor pode explorar uma vulnerabilidade de SQL Injection inserindo o seguinte no campo de usuário:
' OR '1'='1
Após a injeção, a consulta SQL poderia se tornar:
SELECT * FROM usuarios WHERE usuario = '' OR '1'='1' AND senha = 'senha_digitada';
Neste caso, '1'='1' é sempre verdadeiro, então a consulta retornará todos os registros da tabela usuarios, ignorando a necessidade de uma senha válida para o login.
Impactos do SQL Injection:
- Leitura Não Autorizada de Dados: Um invasor pode ler dados sensíveis que não deveriam ser acessíveis como senhas, dados bancários e demais informações pessoais.
- Modificação de Dados: Dados existentes podem ser modificados ou excluídos, comprometendo a integridade dos dados.
- Execução de Comandos Arbitrários: Comandos SQL maliciosos podem ser executados, potencialmente permitindo o controle total sobre o banco de dados.
Como identificar um possível SQL Injection
Muitas vezes não há sinais óbvios visíveis externamente para identificar um SQL Injection. No entanto, existem algumas técnicas e sinais que podem ajudar a identificar se um sistema está vulnerável a SQL Injection. Para detectar manualmente a vulnerabilidade podemos inserir nas consultas:
- O caractere de aspas simples ' e procurar por erros ou outras anomalias.
- Alguma sintaxe específica de SQL que avalia o valor base (original) do ponto de entrada e um valor diferente e procura diferenças nas respostas do aplicativo.
- Condições booleanas, como OR 1=1 e OR 1=2, e procurar diferenças nas respostas do aplicativo.
- Payloads projetadas para adicionar atrasos quando executadas em uma consulta SQL e procurar diferenças no tempo necessário para responder.
Ferramentas de segurança especializadas também podem ser utilizadas, como scanners de vulnerabilidades, que podem identificar automaticamente potenciais vulnerabilidades de SQL Injection através da análise de código e interação com o aplicativo.
Outros tipos de SQL Injection
Blind SQL Injection
Muitas vezes, instâncias de SQL Injection são "vulnerabilidades cegas". Isso significa que o aplicativo não retorna os resultados da consulta SQL ou os detalhes de quaisquer erros de banco de dados em suas respostas. Vulnerabilidades cegas ainda podem ser exploradas para acessar dados não autorizados, mas as técnicas envolvidas geralmente são mais complicadas e difíceis de executar.
As seguintes técnicas podem ser usadas para explorar vulnerabilidades de Blind SQL Injection, dependendo da natureza da vulnerabilidade e do banco de dados envolvido:
- Você pode alterar a lógica da consulta para acionar uma diferença detectável na resposta do aplicativo, dependendo da verdade de uma única condição. Isso pode envolver a injeção de uma nova condição em alguma lógica booleana ou acionar condicionalmente um erro, como uma divisão por zero.
- Você pode acionar condicionalmente um atraso de tempo no processamento da consulta. Isso permite inferir a verdade da condição com base no tempo que o aplicativo leva para responder.
Second-order SQL injection
O SQL Injection de primeira ordem ocorre quando o aplicativo processa a entrada do usuário de uma solicitação HTTP e a incorpora em uma consulta SQL de maneira insegura.
Já o SQL Injection de segunda ordem ocorre quando o aplicativo recebe a entrada do usuário de uma solicitação HTTP e a armazena para uso futuro. Isso geralmente é feito colocando a entrada em um banco de dados, mas nenhuma vulnerabilidade ocorre no ponto em que os dados são armazenados. Mais tarde, ao lidar com uma solicitação HTTP diferente, o aplicativo recupera os dados armazenados e os incorpora em uma consulta SQL de maneira insegura. Por esse motivo, o SQL Injection de segunda ordem também é conhecida como injeção SQL armazenada (Stored SQLi).
Mitigação e Prevenção:
Para evitar ataques de SQL Injection, é crucial adotar práticas de segurança sólidas, como:
-
Uso de Parâmetros SQL e Prepared Statements: Em vez de concatenar strings diretamente em consultas SQL, use parâmetros ou prepared statements fornecidos pelo seu framework ou linguagem de programação. Isso ajuda a separar os dados da lógica da consulta SQL e evita que o código malicioso seja executado.
-
Validação e Sanitização de Dados: Sempre valide e sanitize os dados de entrada antes de incorporá-los em consultas SQL. Isso inclui usar funções como
mysql_real_escape_string()(no MySQL antigo), ou preferencialmente, utilizar os métodos de escape fornecidos pelos ORM (Object-Relational Mapping) modernos. -
Princípio do Menor Privilégio: Limite as permissões de acesso ao banco de dados para que os aplicativos usem apenas as operações necessárias.
-
Auditoria e Monitoramento: Implemente auditorias regulares de segurança e monitore o tráfego de dados em busca de atividades suspeitas.
Referências
- https://portswigger.net/web-security/sql-injection